CSAPP 存储器层次结构
本文最后更新于:2022年7月6日 下午
CSAPP 第六章 存储器层次结构
第六章 存储器层次结构

磁盘

磁盘一般会有多个盘面,与之对应每个盘面都会有一个对应读/写头,读/头在传动臂的末端,且它会位于盘面0.1微米的高度告诉飞翔。进一步说,盘面上一粒微小的灰尘对它来说都是一块巨石,如果它遇到这块大石,那么就会停顿下来,撞到盘面-所谓的读/头冲撞,所以磁盘总是密封的
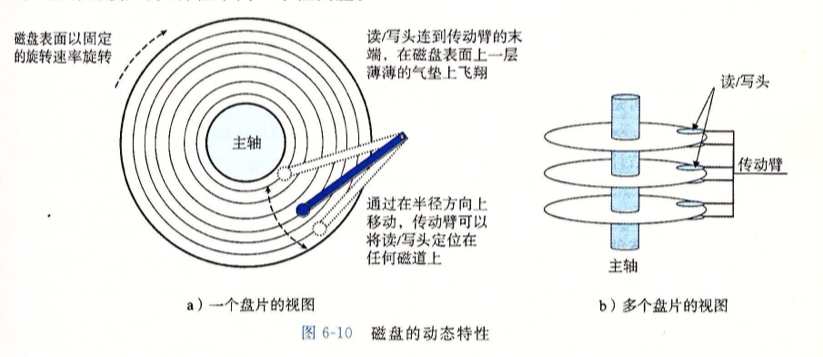
磁盘的读取是以扇区为单位的,而影响扇区的读写时间有以下三部分组成
寻道时间:传动臂移动到对应磁道的时间,通常为3-9ms,最差的时间为20ms
旋转时间:当读写头定位到了期望的磁道上时,去要等待目标扇区的第一位旋转到读写头下,这取决于读写头旋转到盘面时位置以及磁盘的旋转速度,最坏的情况下,目标扇区刚刚错过读写头,需要完整的等待磁盘旋转一圈
传送时间:当目标扇区位于读写头的第一位时,就可以开始读写该扇区的内容了,这个时间取决于旋转速度和每条磁道的扇区数量(扇区大小)
访问磁盘
当cpu需要向磁盘访问数据的时,例如1Ghz的处理器,每个时钟周期为1ns,而从磁盘中读取数据需要16ms,这些时间够cpu执行1600w条指令了,如果CPU一直在等待数据的返回,显然是一种访问,此时CPU把读取数据的操作交给DMA(直接内存访问)去做,它会从给定的目标地址中将对应的扇区数据安全的传输到主存中,当传输完成之后,DMA会向CPU引脚发送一个中断信号,让CPU中止当前的任务,然后将控制返回到CPU被中断的地方
访问机械硬盘
I/O总线磁盘控制器
先找到对应的盘面
再在对应的盘面将机械臂抬到对应的磁道 (寻道)
找到对应的扇区
将扇区的一整个数据读出
访问固态硬盘
I/O总线闪存翻译层
闪存 (由
N个块的序列组成的)块 (由
32 ~ 512个页组成,所以大小为16KB ~ 512KB)页 (
512B ~ 4KB大小)然后将一整个页的数据读出
固态硬盘的读写单位是页,如果要从将一个数据写入某个页中,需要这个页所属的块整个被擦除(所有其它位都设置为1),才能够进行读写。也可以直接对这一整个块进行擦除,在进行大约10w次重复写之后,这块就会被损坏,就不能再被使用了

固态硬盘的随机写要比随机读更慢,1ms级别的,比随机读慢上一个量级
固态硬盘相比机械硬盘有很多优点,它是半导体存储器构成的,没有移动部件,所以随机访问时间比机械硬盘更快,能耗更低,也更结实。但它也有缺点,闪存块在反复写之后,闪存块会磨损,寿命会下降。所以闪存翻译层有一个平均磨损(wear leveling) 逻辑通过平均的擦除闪存的所有块来尽可能最大化每个块的寿命,它的表现很好,SSD通常要很多年才会坏。
目前很多设备都已经开始采用固态硬盘来代替传统的机械硬盘的,例如便携式音乐设备等,再加上国产厂商也可以制造固态硬盘,价格也开始下来了,现在的笔记本也基本上都是固态硬盘为主了。资料备份,或者监控,nas等场景还是使用传统的机械硬盘更好一些。
局部性
时间局部性
空间局部性
程序中对数据引用的局部性
对于一层循环,一般来说都具有简单的空间局部性,如下面这段代码,每次循环i都会加一,这种就被称为,我们也把步长为1的引用模式称为顺序引用模式。一般而言,步长不断增加,空间局部性也会不断下降**
int sum = 0;
for(int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){
sum += arr[i]
}以上代码同时也具有很强的时间局部性,因为循环体会被执行多次,所以对应的指令也会被执行多次
重复引用相同的变量
对于具有
步长为N的程序,步长越小,空间局部性越好,步长越大,空间局部性越差对于取指令来说,循环有良好的空间和时间局部性,循环越长,同时循环体越小,局部性就越好
存储器层次结构中的缓存
缓存被分为多层,从L0 一直到远程服务器,第i层会缓存i+1层的数据,例如本地磁盘会远程远程服务器上的数据,每层的存储器被划分为连续的数据对象块,每个块都有唯一的地址或名字,块可以是固定大小的(位于本地上的存储器),也可以是可变大小的(远程服务器)。
第i层会比i+1层更小,也就以为着只能缓存一部分i+1层的块,例如L0和L1传送的是1个字节大小的块,而L2和L1传送的几个字节的块
web浏览器的缓存利用的就是时间局部性,从硬盘中取数据比从remote取数据要快
缓存命中
如果第i层缓存没有数据,同时缓存容量已满,则会向第i+1层获取数据,同时覆盖现有的一个块
覆盖的过程被称为替换或者驱逐,具体如何替换取决于替换的策略。例如,采用随机替换策略,就会随机替换某一个块,如果采用最近最少访问策略LRU,就会把最后被访问的块替换掉。
空缓存/冷缓存 强制性不命中/冷不命中
放置策略,
CPU缓存的放置策略都是通过硬件来实现的有一种严格的硬件缓存放置策略,它给
i+1层的缓存限制了放置区域,类似于4人一组,那么A组的块就会被放置到第0个块中,B组的块就会被放置到第1块中。这种放置策略也会有弊端,如果第一次访问了A组的块。然后第二次又访问了A组的块,那么对这两个块每次引用都会不命中还有一种不命中的情况,例如访问多维数组,这个块的集合称为这个阶段的工作集,如果这个工作集的大小超过了缓存的大小就会出现容量不命中。意思就是缓存太小了,不能处理这个工作集
高速缓存的查询步骤
组选择
行匹配
字抽取
缓存器会被设计成包含多个组,每个组有一个或多个行,而每个行包含有效位和标记位及多个块组成,如下图所示
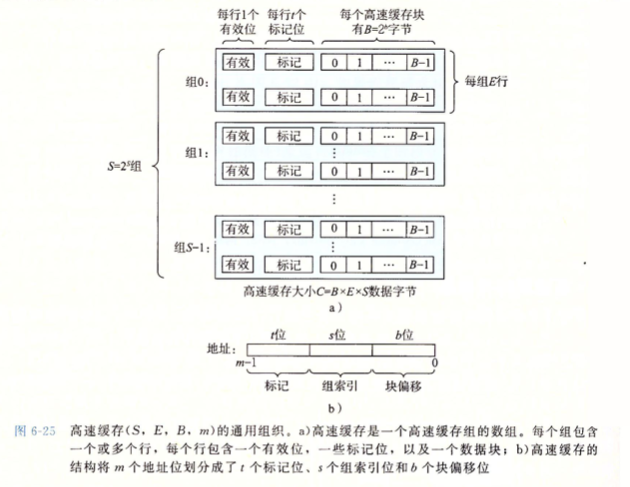
直接映射高速缓存
如果CPU要从地址A中读取一个字时,CPU会将这个地址发给高速缓存,高速缓存会把这个地址解析成包含 标记,组索引,块偏移的一个数据结构,直接映射高速缓存的特性是每组只有一个缓存行
上述说过高速缓存会先进行组选择,那么就会通过这个地址的组索引组找到对应的组,以下假设地址为32位
这个地址的组索引会通过固定的方式来获取,例如取地址的
中间 8位作为组索引, 同时缓存器中被分为4个组,那么多个不同的地址,可能会被缓存到同一个缓存组
在行匹配的时候,会通过标记位来判断该组时候含有匹配的行
标记位也可以从地址中取,一般会取地址的高位,也就是没有用来检索索引组的位,例如使用地址的
高18位作为索引
当标记位也命中,说明该行已经有这个地址的缓存,此时再通过块偏移,去找到位于这个地址在这个块的具体位置
块偏移可以采用地址的
低2-5位,也就是说低地址的0-2位没有被使用
为什么采用中间位作为组索引,而不采用高地址?
因为采用高地址,会把相邻的地址缓存到同一个组,这样就容易出现冲突不命中,缓存失效的情况。如果一个具有良好空间局部性的程序开始运行,顺序扫描一个数组的话,那么在任何时间,高速缓存只能保存一个块大小的内容。(因为高地址位相同),而采用中间位则总是可以将相邻的地址映射到不同的组,使缓存的利用率更高

如题,在一个16MB的内存中,这个cache有64kb,其中每个块是4kb。
因为它说这个chche限定只有64kb,且是由若干个4kb的块组成的。那这个cache就是 64/4 一共有16个4kb的块
因为一个块是4kb可以用$2^2$次方表示,16个块就是$2^{16}$次方。进一步说,只需要16位就可以完全表示出64kb的地址(如果是32位的地址话,就会把高16位舍弃掉)
块偏移需要一个块的大小,也就是要2位,会使用低地址的2位
那么剩下的14位就是索引位。
被舍弃掉的高16位会被用来当标记位
组相联
组相联的每个组的行都是包含两个或两个以上的
在行匹配的时候会搜索所有行,直到标记位匹配,如果全部搜索完毕都没有搜索到,那么就是缓存未命中,会去内存中取出这个字的块
取出这个块之后,如果组中有空闲的行,则直接把这个块放到空闲行中,如果没有空闲行的话,那么就需要从中替换掉非空的行。
具体如何替换取决于具体的替换策略,例如最简单的替换策略是随机选择要替换的行,其它更复杂的策略利用的局部性原理,例如最不常使用(LFU, 单位之间内使用最少的行),和最近最少使用(LRU,最近访问时间最久的那个行),这些策略都需要额外的时间和硬件,但是和需要去更下一层存储器结构中找,用更好的策略来使得提升缓存命中也就变的更值得了
全相联高速缓存
没有组索引,一个组中包含所有的行
它的行匹配和组相联一样,它们区别是规模大小问题。
因为它会并行的搜索所有相匹配的行,所有如果这个行规模太大的话,这个高速缓存的实现成本就很高。所以一般这种方式只时候做小一点的高速缓存。虚拟内存中的TLB就是全相联高速缓存
关于高速缓存的写
上述都是讲的高速缓存的读,高速缓存的写就会更复杂一些了,如果我们要写一个高速缓存中的字(写命中 write hit),在当前一级的缓存器中将该值更新后,怎么更新更低一级中的副本呢,有两种常见的策略
直写,直接将更低一级的缓存副本进行更新,这种方式很简单,但是每次写都会引起
I/O总线流量写回,直到该缓存行被替换时才将更低一级的副本进行更新,这种方式需要在缓存行中多加一个修改位,用来标记是否修改过
处理写不命中
如果发生写不命中,也有两种常见的策略
写分配(
write-allocate),直接将下一级缓存中的副本加载到当前缓缓存器,然后将该缓存行进行更新,它利用了局部性原理,缺点是每次都要从底层往高层传递块,会引起I/O总线流量非写分配(
not-write-allocate),直接将这个字写在它当前的缓存器中不往上传送
如何为缓存器优化写操作是细致而困难的问题,具体实现取决于系统,而且通常这些具体的优化是不公开的,文档也不详细,所有我们只需要学习大致的理念以及基本的写方式就ok了,我们可以在更上层写出局部性更优的程序,而不需要花太多时间想怎么为一个存储器进行优化
真实缓存的解剖
i-cache,缓存指令 (通常是只读的)
d-cache,缓存数据
unified-cache,既缓存数据,又缓存指令(统一的高速缓存)
例如高端处理器的 L1会被划分为指令缓存和数据缓存,L2和L3是统一的高速缓存
将缓存进行这样的区分可以让CPU在同一时间读取指令缓存和数据缓存而不会相互影响,但是正因为进行了这样的区分,会导致另一片缓存的空间更小,会出现更多的容量不命中
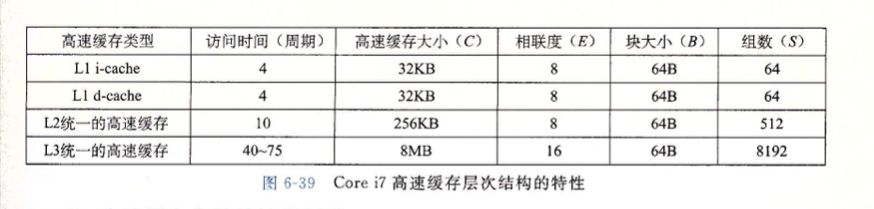
影响高速缓存的点
高速缓存的大小
如果高速缓存很大,则没有很好的方法优化其读写速度,且更大的高速缓存同时会增加命中时间。这也就是为什么L1比L2小,L2比L3小
块的大小
大的块有利也有弊,如果块被分的很大, 那么越可能会吃到空间局部性带来的红利,但同时也表示缓存行可能可能会更少。这会增加时间局部性更优的程序缓存不命中率。同时较大的块对高速缓存传输也会带来一定的影响,较大的快需要更多的时间进行传输
相联度影响
这里指的的每个组的缓存行数,如果缓存行数越大,会降低缓存不命中出现抖动的可能性。如果与之而来的时候命中时间的增加,缓存行更多标记位的增加,缓存行置换的硬件和逻辑增加。
所以一般高性能处理器都会为L1高速缓存使用较低的相联度,而在缓存未命中惩罚较高的缓存采用高相联度。例如 Inter Core i7的L1和L2是8路组相联的,L3是16路组相联的
写策略
写不命中的开销比较大,如果是直写缓存,实现起来比较简单,而且可以用独立于高速缓存中的写缓冲区(write buffer)来更新内存。
如果是写回策略,它引起的传送比较少,它允许更多的到内存的带宽用于执行DMA和I/O设备,且层次越低,传送时间久越长,所以减少传送的数量就变得很重要
一般而言,数据越底层,越可能使用写回,而不是直写
在程序中利用局部性
i7处理器拥有预取功能,能够提前取出步长为n的索引模式,例如提前取出可能会循环的数组
多注意循环体内部,大部分计算和内存访问都集中在这
通过数据存储在内存中的顺序,尽可能的采用
步长为1来读数据,使程序中的空间局部性最大一旦从内存中读了某个数据,就尽可能的多使用它,使时间局部性最大
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处。