CSAPP 处理器体系结构
本文最后更新于:2022年7月6日 下午
CSAPP 第四章 处理器体系结构
第四章 处理器体系结构
早期的RISC指令集没有较长延迟的指令,甚至加法乘法都需要编译器通过加法的累加来实现
cpu的时钟周期
我们把取出指令、分析指令、执行指令这三个过程称为一个 CPU 时钟周期。CPU 是永不停歇的,当它执行完成一条指令之后,会立即从内存中取出下一条指令,接着分析该指令,执行该指令,CPU 一直重复执行该过程,直至所有的指令执行完成。
cpu如何执行指令
cpu中有一个****寄存器,用来记录内存中的地址,当cpu按照这个地址取出指令后,然先将下一条指令更新
将下一条指令更新后,cpu就会开始分析指令,并识别出不同类型的指令,以及各种获取各种操作数的方法,然后将其存放在通用寄存器,cpu访问通用寄存器很快,其次是 l1缓存,l2缓存,l3缓存,内存,硬盘,remote
Y86-64 的顺序实现
处理一条指令的顺序
取值(fetch) 从内存中读取指令字节
译码(decode) 最多从寄存器中读两个操作数
执行(execte)
算术/逻辑单元(ALU)可能会执行指令指明的操作,计算内存引用的有效地址,要么增加或减少栈指针访存(memory) 可以将数据写入内存和从内存取出
写回(write back) 最多将两个结果写到寄存器文件
更新 PC寄存器(PC update) 更新下一条
pc指令
处理器无限循环去执行这些阶段,如果遇到错误,会执行一些指定的错误逻辑
分支预测
分支预测可以在指令出现分支在计算时,处理器可以大胆的往后进行预测,如果预测成功了,那么就可以全速的继续向后执行。但是即使是最好的分支预测技术也会出错,这个被称为误判惩罚如果预测失败则需要回退,如果流水线的阶段过多,那么分支预测失败的时候需要回退的就越多
最简单的预测就是假设分支不会发生,这种方式有
50%左右的成功率,这种方式称为静态分支预测1比特饱和计数,这种方式是记录上一次分支的结果,然后假设此次的结果也会是和上次一样2比特饱和计数,它会通过最近两次的结果来判断此次的结果,这种方式的准确率高达93.5%随机分支预测,每个分支都有
50%的几率
这里有关于分支预测器更多的内容 https://en.wikipedia.org/wiki/Branch_predictor
说完了分支预测,我们来看一下一段这样循环代码
let start = Date.now()
for (let i = 0; i < 100; i++) {
for (let j = 0; j < 1000; j++) {
for (let k = 0; k < 10000; k++) {}
}
}
console.log('循环1:', Date.now() - start)
start = Date.now()
for (let i = 0; i < 10000; i++) {
for (let j = 0; j < 1000; j++) {
for (let k = 0; k < 100; k++) {}
}
}
console.log('循环2:',Date.now() - start)两个循环的次数是一样的,第一个循环将第一层循环了100次,第二层循环了1000次,第三层循环了10000次
第二个循环将第一层循环了10000次,第二层循环了1000次,第三层循环了100次。
可以看到以下耗时,可见第一个循环的耗时明显比第二个短,因为第一个循环的分支预测
循环1:319 ms
循环2:369 ms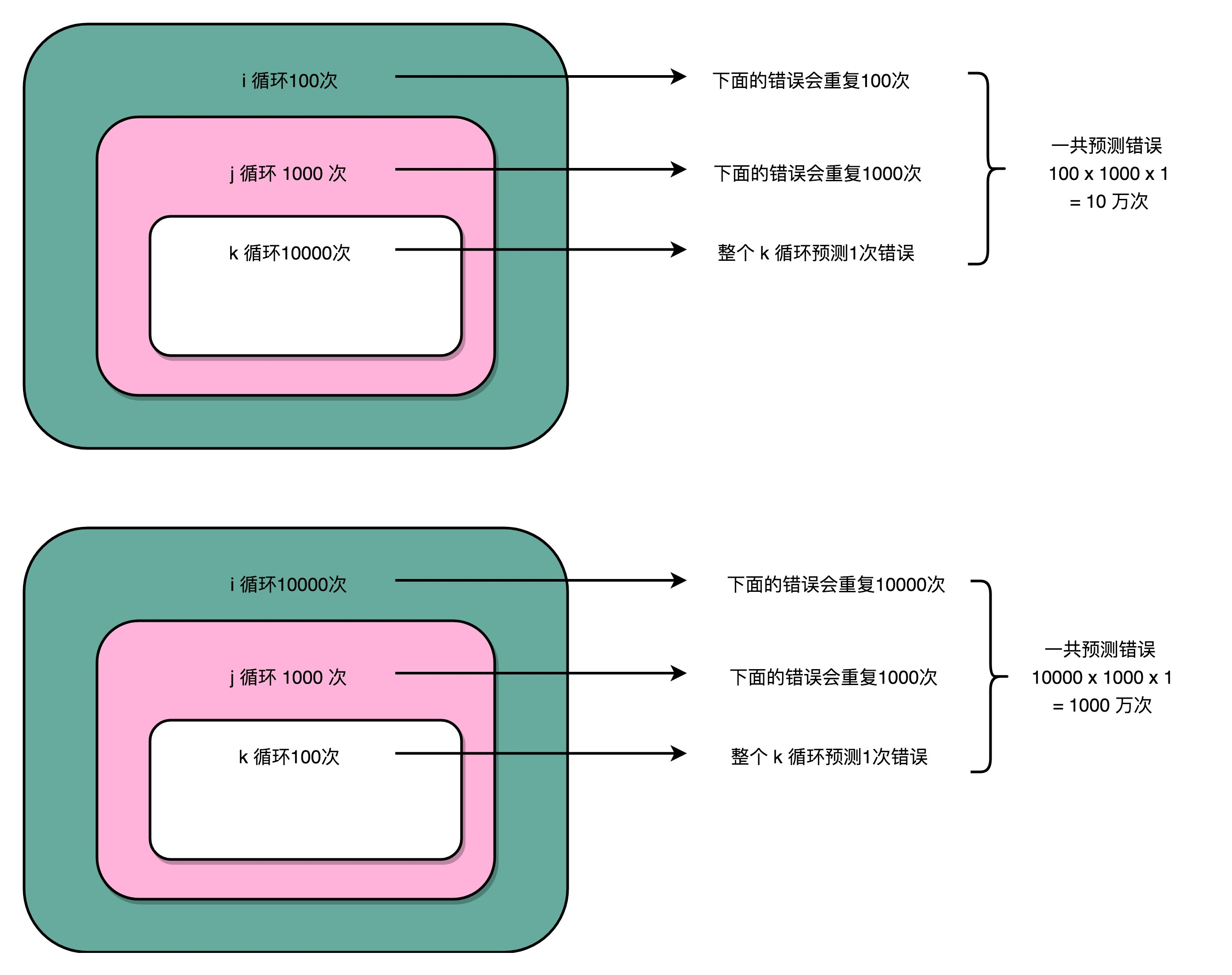
分支预测最简单的策略就是假设分支不会发生,那么第一个循环的中的最内存循环在循环到1000次的时候才会出现一次分支
流水线
一条指令会被分解成
取值
解码
执行
写回
如果每条指令都被分成这4个阶段的话,这样就可以采用流水线的技术来提升性能了
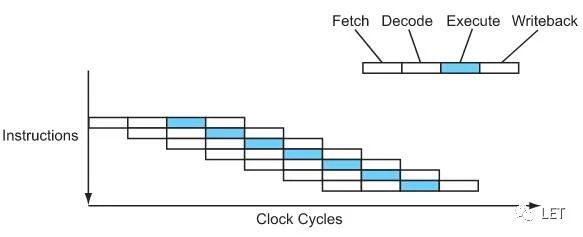
例如A指令在准备解码阶段时,B指令可以进入到取值阶段,这样的话单个指令花费的时间不变,但是性能提升了4倍
我们知道,现在cpu有多达2000+条指令,有些复杂指令的执行时很耗时的,例如浮点数的计算,所以流水线的瓶颈在于最慢的那个指令,所以一般会对复杂指令再进行拆分,结果就是,CPU流水线变长,单位时间内可以运行更多的指令
2000年的时候inter的奔腾4采用这种技术,将流水线增加到31个阶段,但是流水线的增加和性能的提升并不是正相关的
通过流水线,可以把一条指令分解成多个步骤,不需要让其它指令等待,例如洗车服务,冲洗,打蜡,抛光,在A车进行到打蜡时,B车与此同时可以冲洗
但是流水线的级数不是越长越好,因为每个阶段执行完毕都需要将输出记录在流水线寄存器,然后交给下一个流水线处理,所以每增加一节流水线,就要多一个写入流水线寄存器的操作,虽然这个操作很快,只有20ps
流水线阶段的增加同时也会带来其它问题
不一致问题
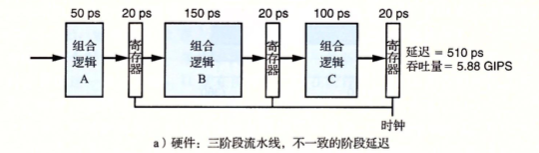
流水线的整体执行由最慢的那个阶段决定,这样就意味着原来执行一条指令可能需要
270ps,通过分成三个阶段后就450ps,所以均匀分配到相同延迟的阶段对硬件设计者也是一项挑战,处理器的某些硬件,如ALU和内存是不能被划分成多个更小的延迟单元的,创建一组平衡的阶段会变得非常困难整体耗时增加
流水线过深的优点是可以将逻辑尽可能的拆分成更简单的组合,这样使得能尽可能的使得每个阶段的延迟都更小。但与此同时,每个阶段中间插入的寄存器也需要一定的耗时,这也会使得整体的耗时增加
例1
例如自助餐取食,必须得按照顺序取,可能某些顾客只想取一些草莓🍓,但是它也必须等待完前面的流程,才能取到草莓,这是流水线带来的轻微延迟。
例2
试想一下当CPU运行以下代码
a = 10000 / 4;
b = a + 1;
c = b + 1;b 和 c 都依赖前一项的结果,乱序执行的CPU在执行的时候就需要把没有相互依赖的指令找出来,放到流水线中,这就意味着如果流水线的长度多达31个,那么就要从待执行的指令中找出31条互不干扰的指令,但是我们的代码大多数情况都是有先后依赖关系的,所以难度一下就大起来了,依赖分析,寄存器重命名会使得CPU设计更为困难,芯片体积更大,额外的逻辑更耗电。这就是为什么流水线的增加并不一定能够直接提升整体性能的原因
有关乱序执行在后续会讲到,可以简单理解成
CPU在将指令放入流水线时会将相互没有依赖的指令一起放入流水线
流水线冒险
流水线冒险 数据冒险
冒泡的方式避免冒险(插入nop)
int a = 1;
int b = a * 10;编译后的汇编代码
.globl _main ; -- Begin function main
.p2align 2
_main: ; @main
.cfi_startproc
; %bb.0:
sub sp, sp, #16
.cfi_def_cfa_offset 16
mov w0, #0
str wzr, [sp, #12]
mov w8, #1
str w8, [sp, #8]
ldr w8, [sp, #8]
mov w9, #10
mul w8, w8, w9
str w8, [sp, #4]
add sp, sp, #16
ret
.cfi_endproc
; -- End function如上代码,第二条指令(第11行)依赖于第一条指令(第8行)的结果,那么第二个指令在执行完取值,译码,在到 执行阶段时发现它依赖的值还没有来,就会暂停(存在数据冒险的情况) 动态的在当前阶段阶段插入一个气泡 nop让这个阶段不会执行任何操作,然后下一个时钟周期再次判断是否有值,如果没有值则重复刚刚的操作,这种方式是通过暂停的方式来避免数据冒险
如果不动态插入一个气泡的话,则会取到错误的值
用转发来实现流水线冒险
例如在B指令的译码阶段运行时,发现了要使用某个寄存器的值,但是当前它还没有值,之前的方式是给它加一个气泡,让它到下一个周期再次尝试取,现在它会发现指令A的写回阶段把这个值算出来了,那么就会直接把这个值作为操作数传入然后继续执行(可以省去一个流水线阶段)
但是有时候会出现当要取某个寄存器的值时,之前执行的流水线确实还没有计算出来,还需要等几个阶段,那么这时候就只有插入气泡了,通过插入气泡和转发结合起来,足以处理所有可能类型的数据冒险,这种方式是 加载/使用数据冒险
控制冒险的回退
如果遇到分支,那么会继续尝试向下运行(预测),取指,译码阶段,但是不会走到执行阶段,因为执行阶段会改变条件码,程序员是可见的(所以此时可能会暂停⏸️,插入气泡),然后等之前的流水线执行完。如果发现不应该选择该分支时就需要回退,回退的处理就是往预测错误指令的执行插入气泡,那么它就不会执行了,同时取出正确的分支放入流水线
多指令周期
一些简单的指令,例如整数的加减,在流水线的执行阶段可以在1个时钟周期内完成,但是一个完整的指令集中,有些指令是一个时钟周期是完成不了的,例如整数的乘除法需要64个时钟周期,浮点数的加法需要3-4个时钟周期。为了实现这些指令,CPU会设计专门的硬件运算单元来处理这些复杂的操作。
如果在流水线的译码阶段发现这是一条乘法指令,那么就会把它发射到,在执行这些操作的时候,流水线会继续执行其它指令。通常这些特殊单元也是流水线化的,因此它们也可以并发执行。
与存储系统的接口
我们程序的代码在运行过程中对一个地址进行读/写的操作其实都是通过虚拟地址来引用的。在理想的情况下,我们可以在CPU一级缓存命中,这样的话确实可以在1-3个时钟周期内完成读或者写的操作。
但是依旧会出现高速缓存不命中(miss)的情况,如果情况好的话,可以在二级缓存,三级缓存,或者再加上TLB(翻译后备缓冲器 Translation Look-aside Bufffer) 中命中,这样的话也可以在3-20个时钟周期内完成,与此同时流水线会在取值或者访存的阶段暂停,直到缓存能够执行读或者写的操作。
但不可避免的是,依旧有可能出现所有缓存未命中,此时就会触发页中断(page fault),CPU 会调用操作系统上的异常处理代码,这段代码会发起一个从磁盘到内存中的传送操作,等到数据传输完成,导致触发页中断的指令会重新执行,但这次访问依旧在高速缓存中无法命中。从磁盘到内存中的数据传送可能需要数百万个时钟周期,所以操作系统会让程序进行中断,所以这对性能几乎没什么影响
乱序执行
乱序执行的详细讲解放在了csapp的后续章节
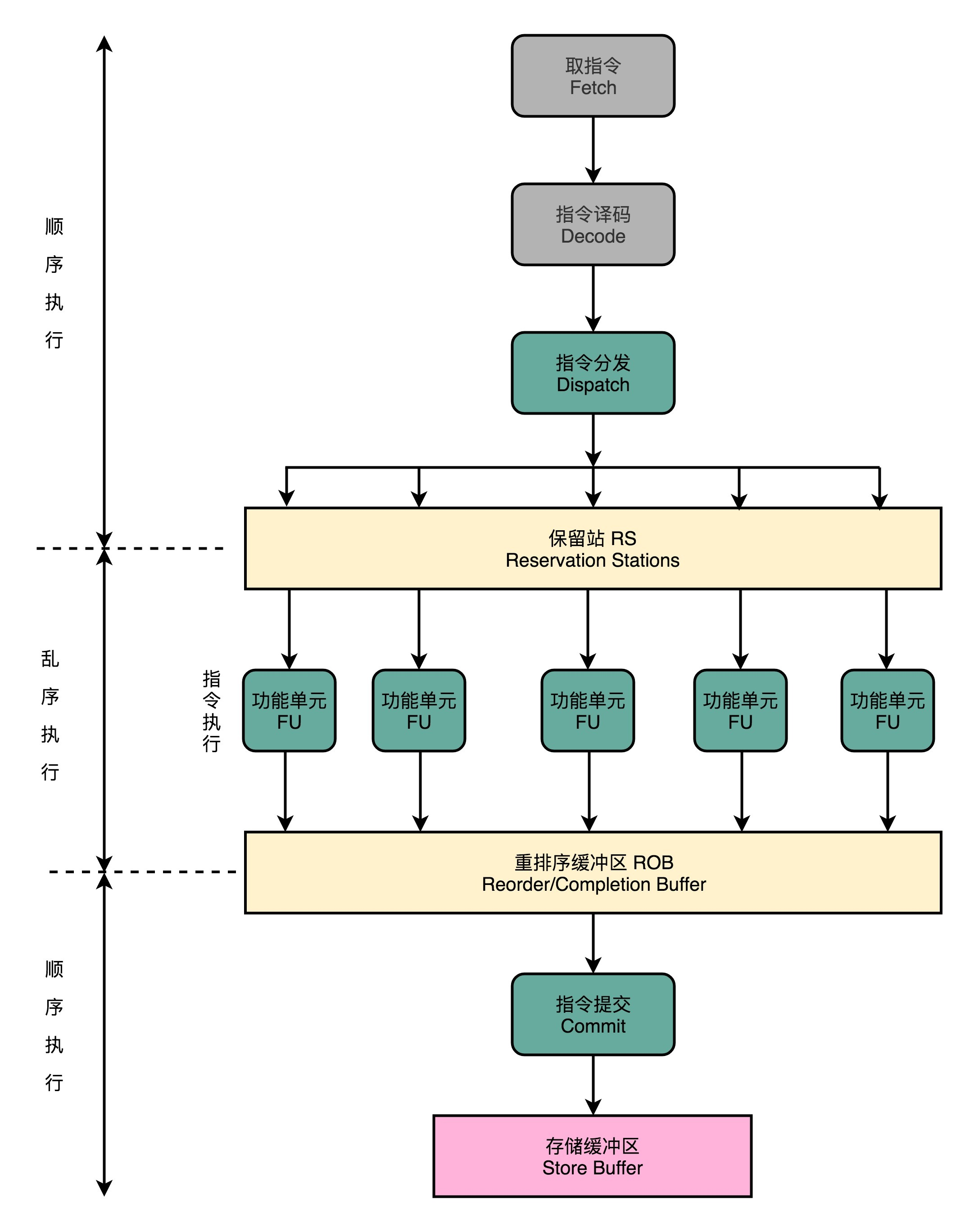
CPU内部结构

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处。