深入学习 garbage collection 的实现
本文最后更新于:2023年2月1日 上午
通过画图的方式学习 GC 的实现
深入学习 garbage collection 的实现
什么是垃圾
程序在运行的过程中,如果不合理的分配内存,则会随着时间的增长,慢慢的堆积垃圾,这部分内容是没有被任何对象引用的,直到堆中的内存达到最大临界
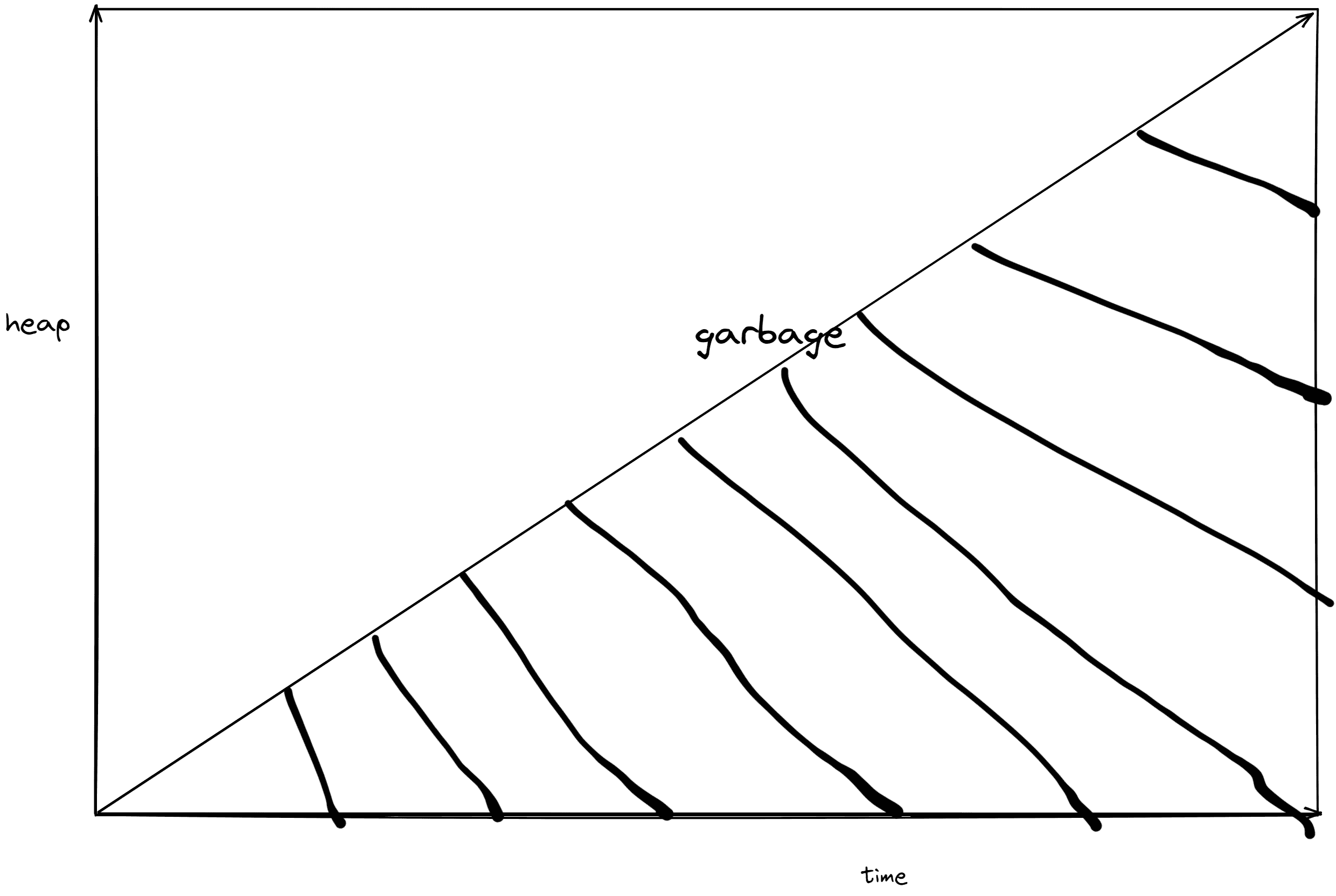
垃圾回收的几种策略
mark-sweep(标记清扫)
mark-copy(标记复制)
mark-compact(标记压缩/整理)
reference-counter(引用计数)
以上4种是主流的垃圾回收策略,一般回收器的实现会在堆中不同的区域使用不同的策略来进行回收。
在学习这四种策略之前,先假设 赋值器 会在一个或多个线程中运行,而回收器只会在一个线程中运行,当回收器work的时候,赋值器会处于停止的状态,这种 “万物静止”("stop the world")的方案大大的简化了回收器的实现。
在赋值器的角度来看,回收器的操作都是原子化的,不会看到回收器操作heap时的中间状态。而回收器在释放内存的时候无需担心其它回收器在同一时刻也在进行释放或者赋值器正在申请新的memory,关于并发回收,以及赋值器和回收器的并发执行会使系统更为复杂,这部分内容在后面进行学习。
mark-sweep
mark-sweep标记清扫 不会直接找到 garbage,它通过指针的可达性从 roots(stack,register, global)** 栈,寄存器,全局变量** 通过 (DFS/BFS)深度优先/广度优先 的方式开始遍历对象图,能够被访问到的对象会被标记为活动的对象。反之,没有被标记到的对象就是garbage,通过该方式间接的找到garbage。
这个算法分为两个阶段
mark阶段,标记所有活动的对象
sweep阶段,将所有未被
mark的对象进行回收
mark 阶段
从垃圾回收器的角度来看,赋值器会做 创建,读,写 3种操作,每种回收算法都会对这3种操作进行合理的重定义,回收器 和 赋值器 之间的接口非常简单,当赋值器进程无法分配内存时,则会唤起回收器,然后再次尝试重新分配内存,如果再次分配失败,则说明堆内存已经耗尽,这通常是一个严重的错误,大部分语言会在这时抛出异常,开发者可进行捕获。

以上是伪代码 ← 是赋值的操作, = 是相等的判断,atomic是原子性操作
如上代码会尝试进行分配,如果分配失败的话,则会唤起gc,再次分配后如果依旧为 null则抛出错误,否则将新地址返回
collect会先标记 roots,将所有的roots对象添加到工作列表(work list)中,标记完成后会进行清扫。

markFromRoots 会先初始化工作列表,将其变为空,然后从遍历 roots的每一个对象,如果该对象不为 null并且未被标记过,则将其标记为活动,再将其添加到 work list中,因为这里采用的时深度优先(DFS)的方式,所以会调用 mark继续遍历该对象所引用的其它对象。
mark 会从 work list中取出一个对象,然后对其引用的其它对象再次进行遍历标记。
标记阶段最终会让 work list变为空,这样的话,所有被标记到的对象就会是活动的对象,所以未被标记到的就是 garbage。
如下图所示,所有被标记到的对象都是存活的对象,未被标记到的对象则是garbage,在清扫阶段会进行回收
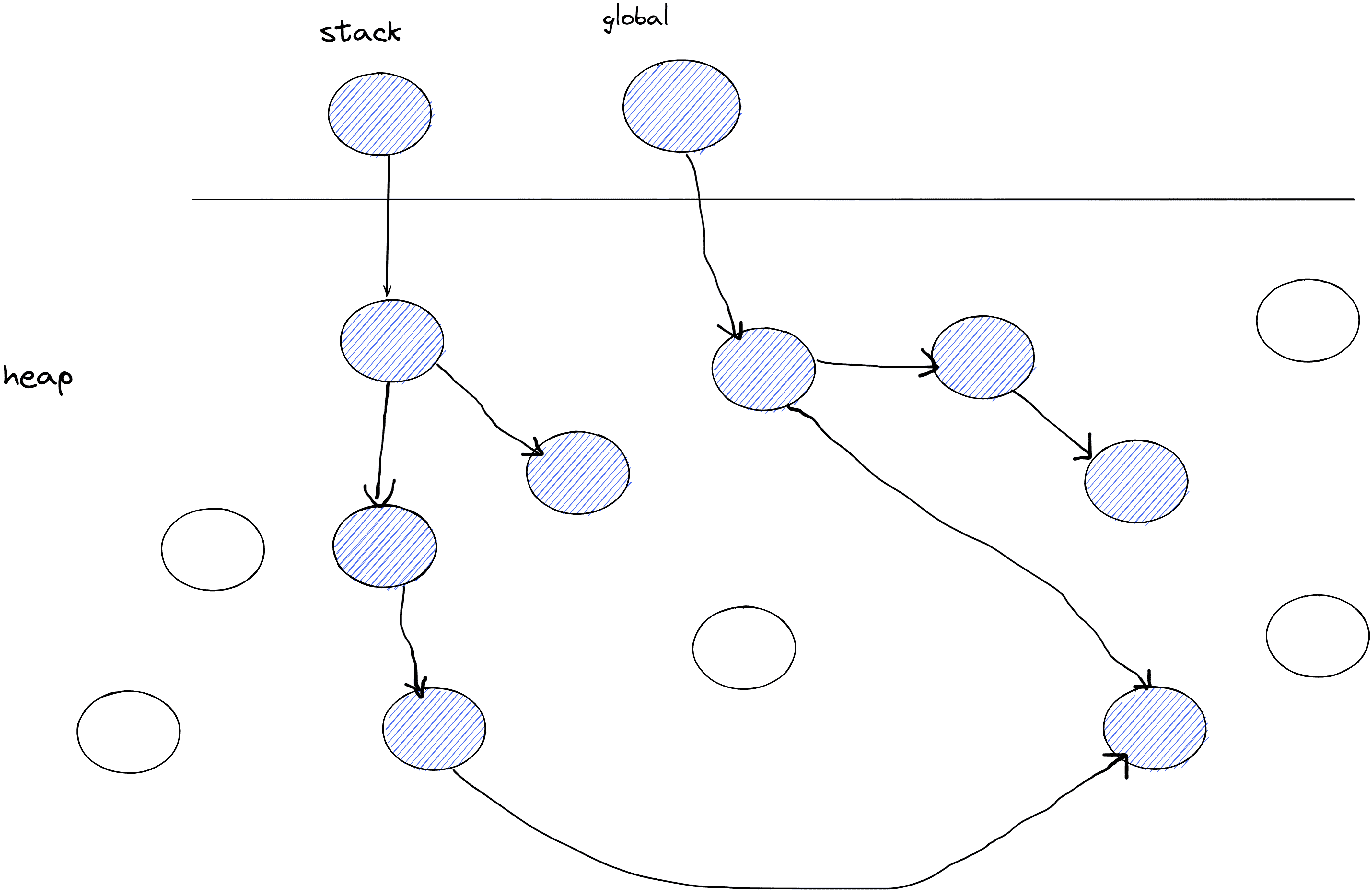
sweep 阶段
当 mark阶段从 roots依次遍历完后,清扫阶段就可以直接清扫所有未被标记的对象,然后将其返回给分配器
回收器通常会从堆底进行线性扫描,即从堆底释放未被标记的对象,同时清空已经被标记的对象,因为下次回收需要重新标记

从堆底开始扫描,如果该对象已经被标记,则将其取消标记。否则将其 free,然后再遍历下一个对象
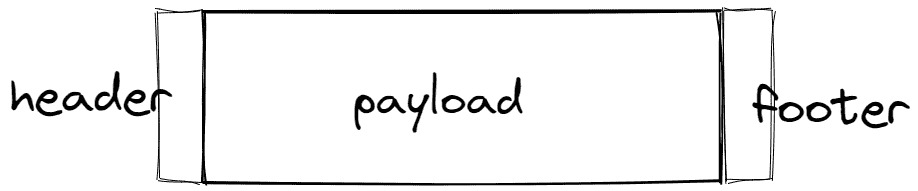
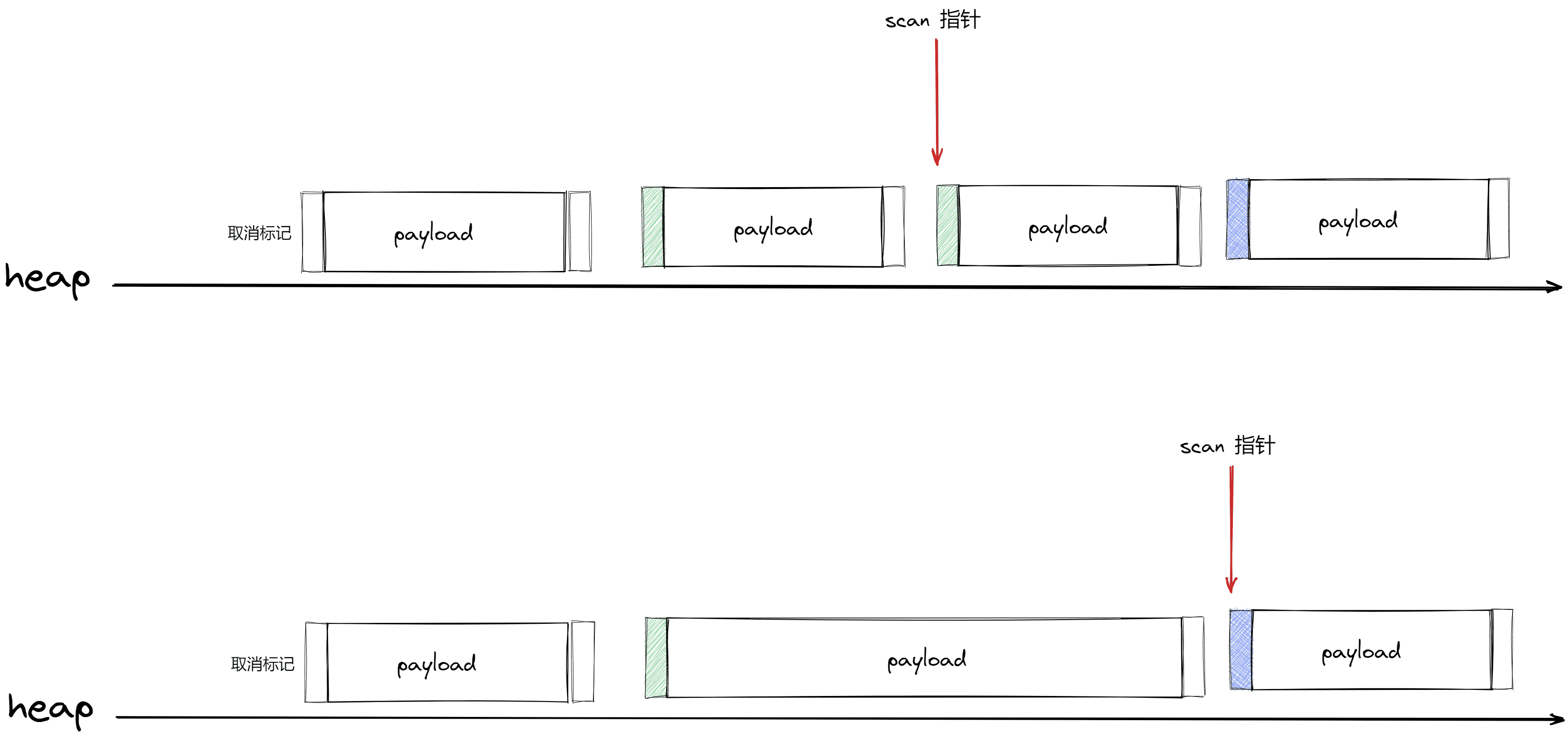
如图所示,每个对象在 heap 中抽象的可以表示为如下图所示 header 中会记录一些一些信息,例如头地址,是否被标记等字段,sweep在工作的时候就可以从 header中读取该对象是否被标记来进行 unMark 和 free的操作
 
sweep准备工作时,heap的空间大致如下图所示
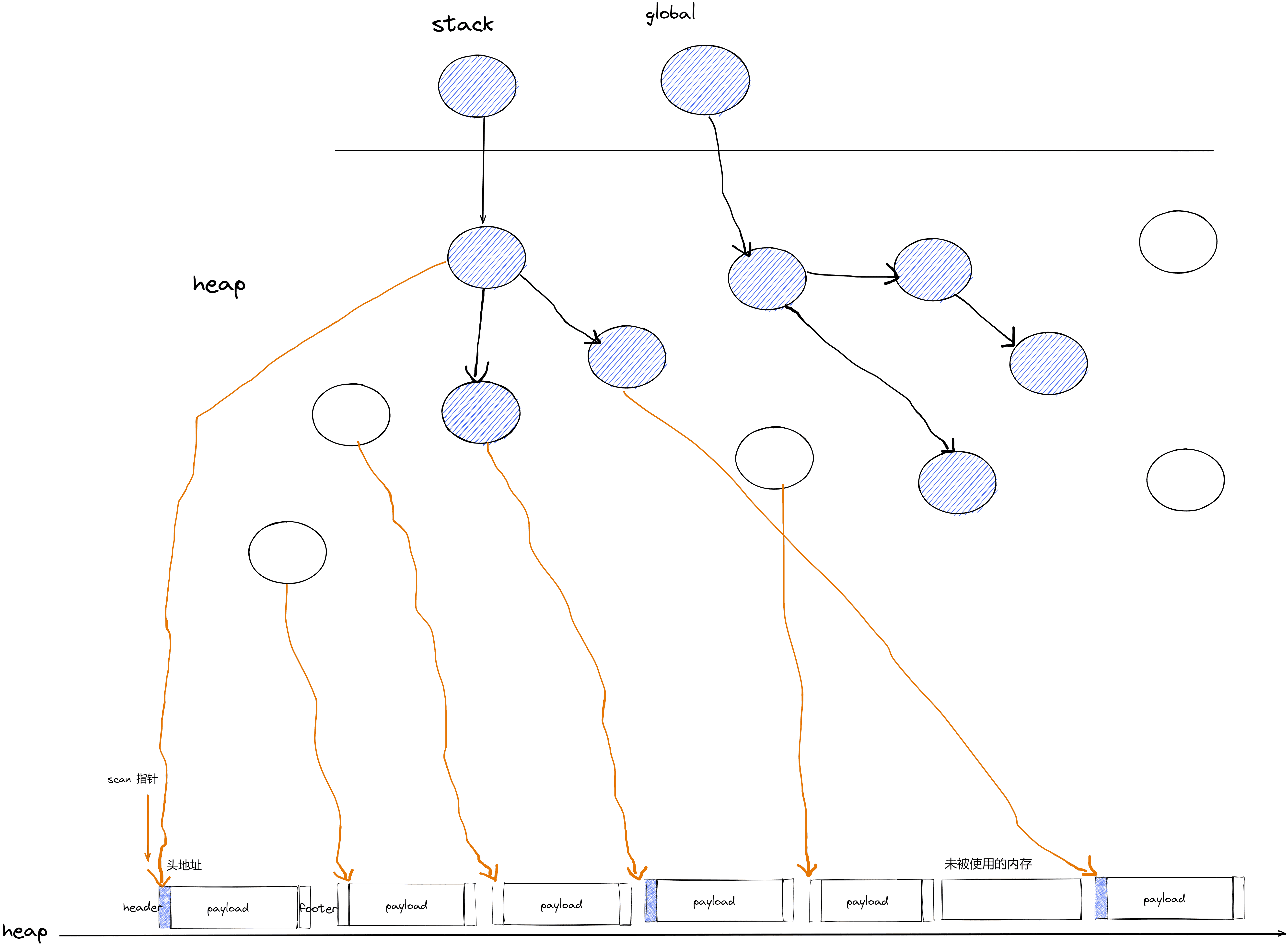
scan从堆底开始扫描,当它发现这个对象已经被标记的话,则会将其设置取消标记,然后再将指针移动到下一个对象 
具体工作如下所示,当 scan 指针指向 被标记的对象时,会将其取消标记,然后指针移动到下一个对象。
当 scan指向未被标记的对象时,则将其 free



此时scan继续扫描下一个对象,如果发现也未标记过, 有些 sweep的实现会在此时查看前一个对象是否也被 free了,如果前一个对象被 free了,则会进行 join,合并成一个大的内存,以供后面进行使用
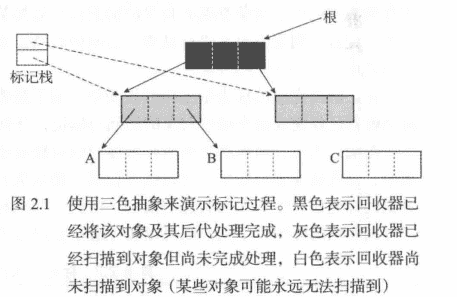
三色抽象标记法
三色标记法,主要是在回收时用来标记对象的状态变化,其中 java的 CMS垃圾回收器和javaScript的v8引擎都用到了该策略,该策略初始化时会将所有的对象都标记为白色,当某一个对象能够从 roots开始访问到,则将其标记为黑色,如果某个对象在标记的过程中(还未标记完成)则是灰色。
完成这样的一轮标记后,回收器就只需要将所有的白色对象进行回收,一次堆遍历可以看作是以灰色对象作为 “波面”,将黑色节点和白色节点分离,不断向前推进波面,知道所有可达的对象变成黑色的过程
mark-compact
mark-compact (标记整理/压缩) 算法主要的是为了降低内存碎片化的问题,之前提到的 mark-sweep标记清除 非移动式回收器 就会产生很多内存碎片。即:尽管堆中任然有很多可用的内存空间,但是内存管理器无法找到一块连续的内存空间来分配较大的对象,或者需要花费较长的时间才能够找到合适的空闲内存。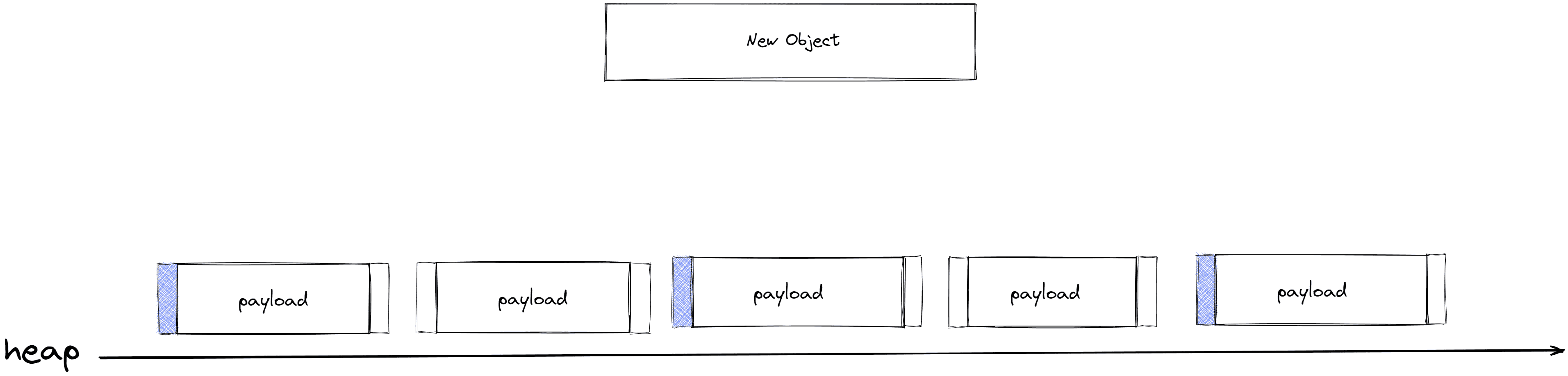
所以,对于长时间运行的程序,采用非移动式回收器来进行内存管理 就会慢慢不断的产生内存碎片。
所以我们可以采用一种对堆中的对象对象进行整理(compact)的一种算法来降低内存碎片的使用,即将 存活的对象移动到堆的一端,将不存活的对象移动到堆的另一端。

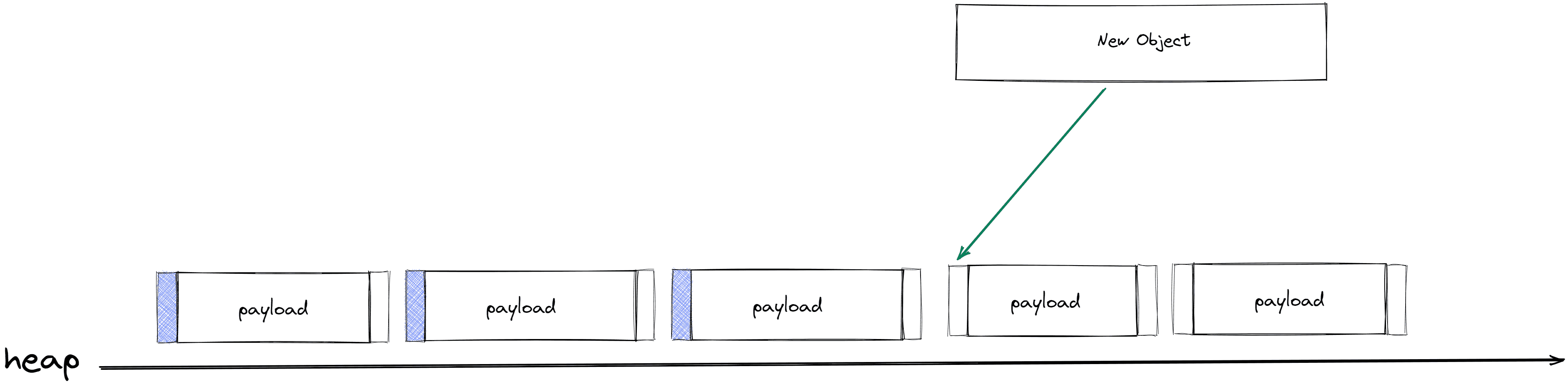

双指针算法
这种算法比较适用于内存空间是固定大小的情况,思路是先计算出所有存活对象所占的内存,然后得到一个高水位标记,高于这个水位的对象将被移动到低水位,如下图所示
算法核心是利用 free 和 scan 两个头尾指针,进行遍历,free在扫描到空闲内存的时候会停下,然后等scan扫描到活动对象,便直接将scan移动到free的位置,上图中有体现,同时在对象的原内存中某个槽中记录转发转发后的地址,即 A → A', 直到scan和free两个指针发生交汇即结束。
这个算法的整理质量在于free的空闲指针和scan对象的大小匹配程度,除非对象的大小固定,否则内存碎片会很高。这个算法不需要使用对象中中的某个槽来保存转发地址,可以直接在原有的内存槽中保持,因为原有的内存槽在后续是不会被使用的
Lisp 2算法
这是一个经典的回收算法,得到了广大的应用,该算法一共需要扫描三次堆。
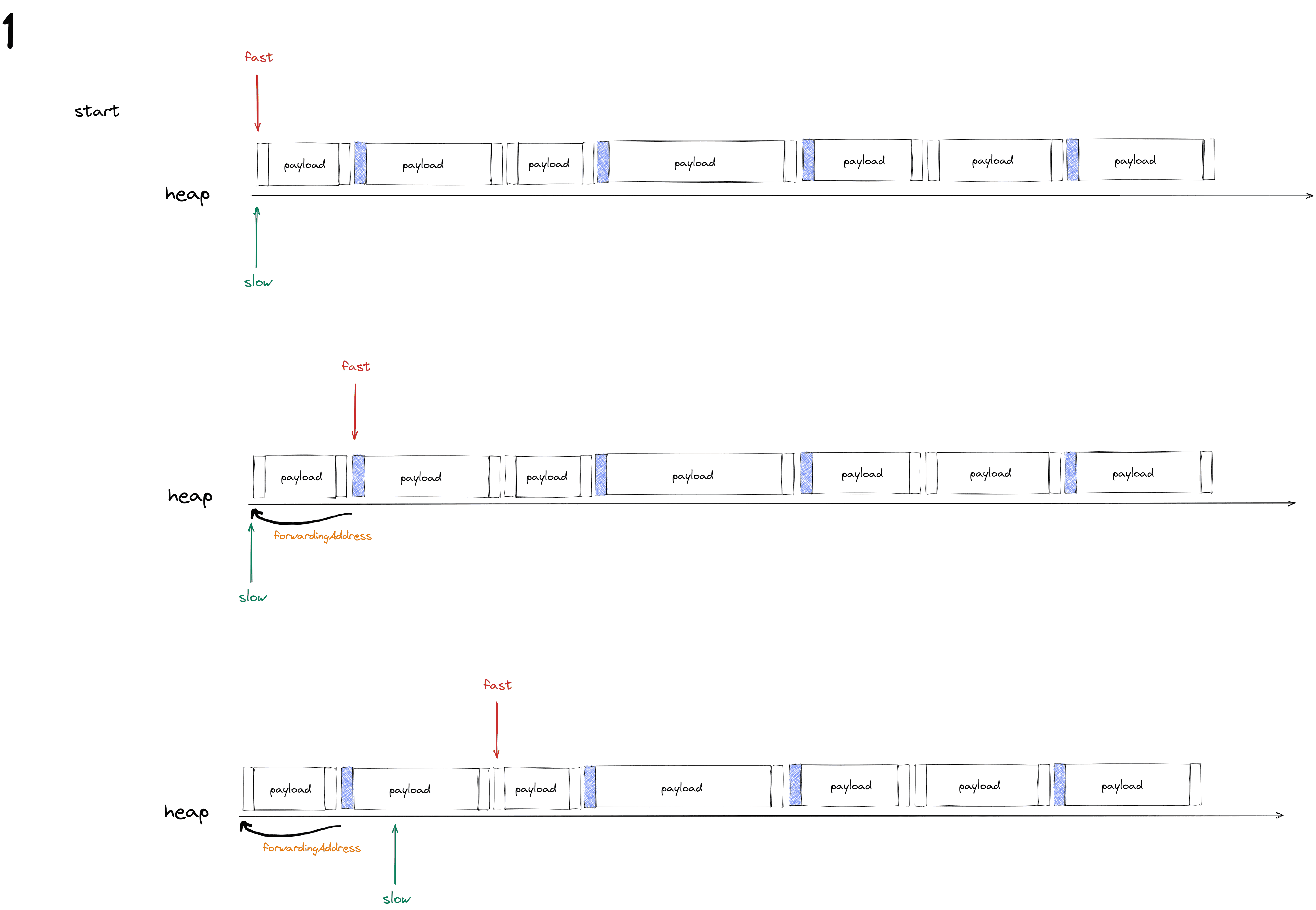
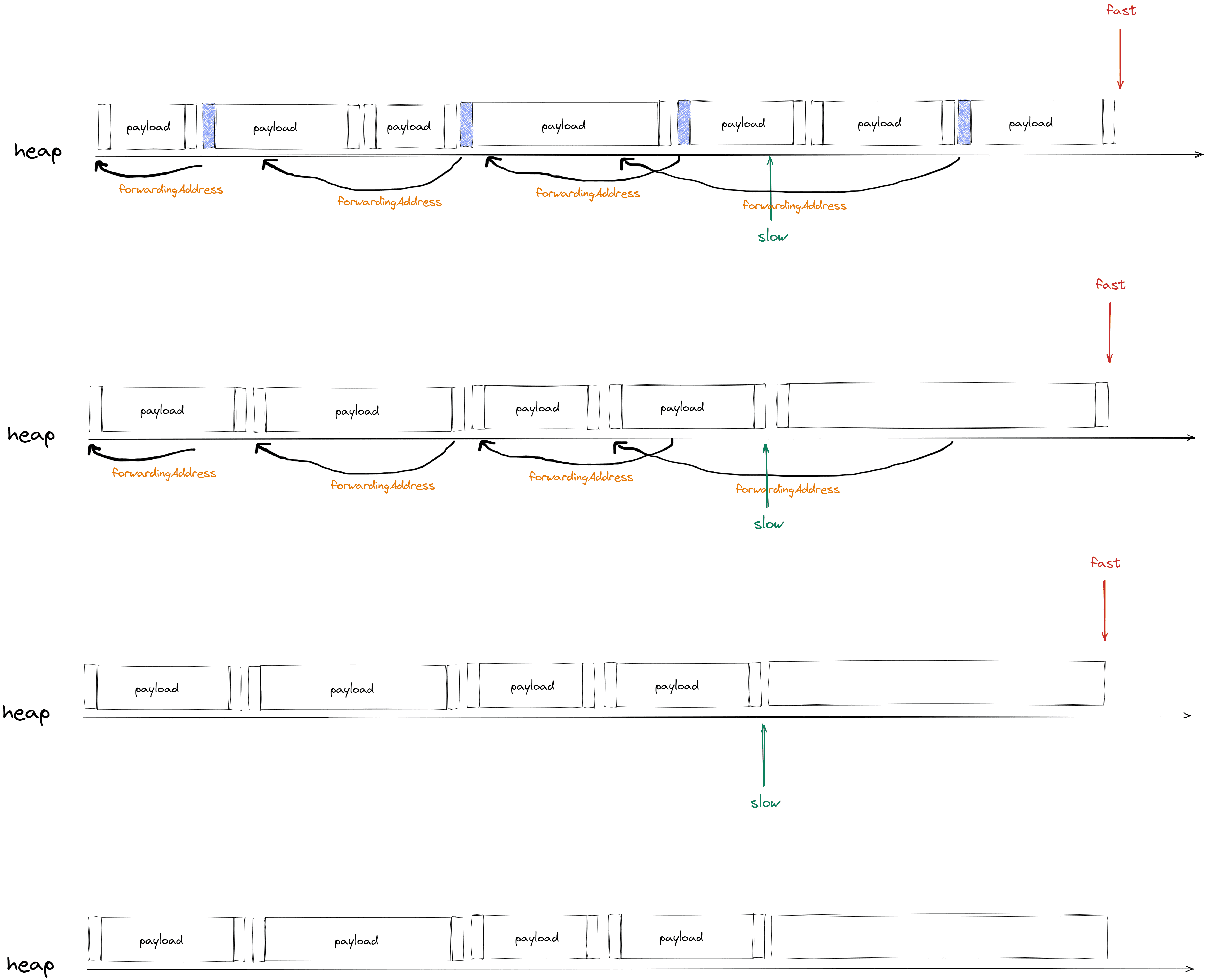
第一次遍历:计算
forwardingAddress转发地址一共两个指针,一个快指针和一个慢指针,快指针会遍历所有对象(标记和未被标记的对象),慢指针只会在快指针遍历到 标记过的对象时才会移动和这个对象同等大小的距离,且在慢指针移动之前,会将慢指针移动之前的地址作为标记对象的
forwardingAddress。在第一次遍历结束后,会计算出所有标记对象的forwardingAddress,同时,快指针已经移动到了堆的末尾,慢指针会移动的位置为所有标记对象的大小总和的位置。第二次遍历:更新 赋值器中对象的引用地址
更新
roots中对象的地址为forwardingAddress转发地址,然后更新所有的标记对象地址为forwardingAddress第三次遍历:移动对象到新的
forwardingAddress转发地址

computeLocations
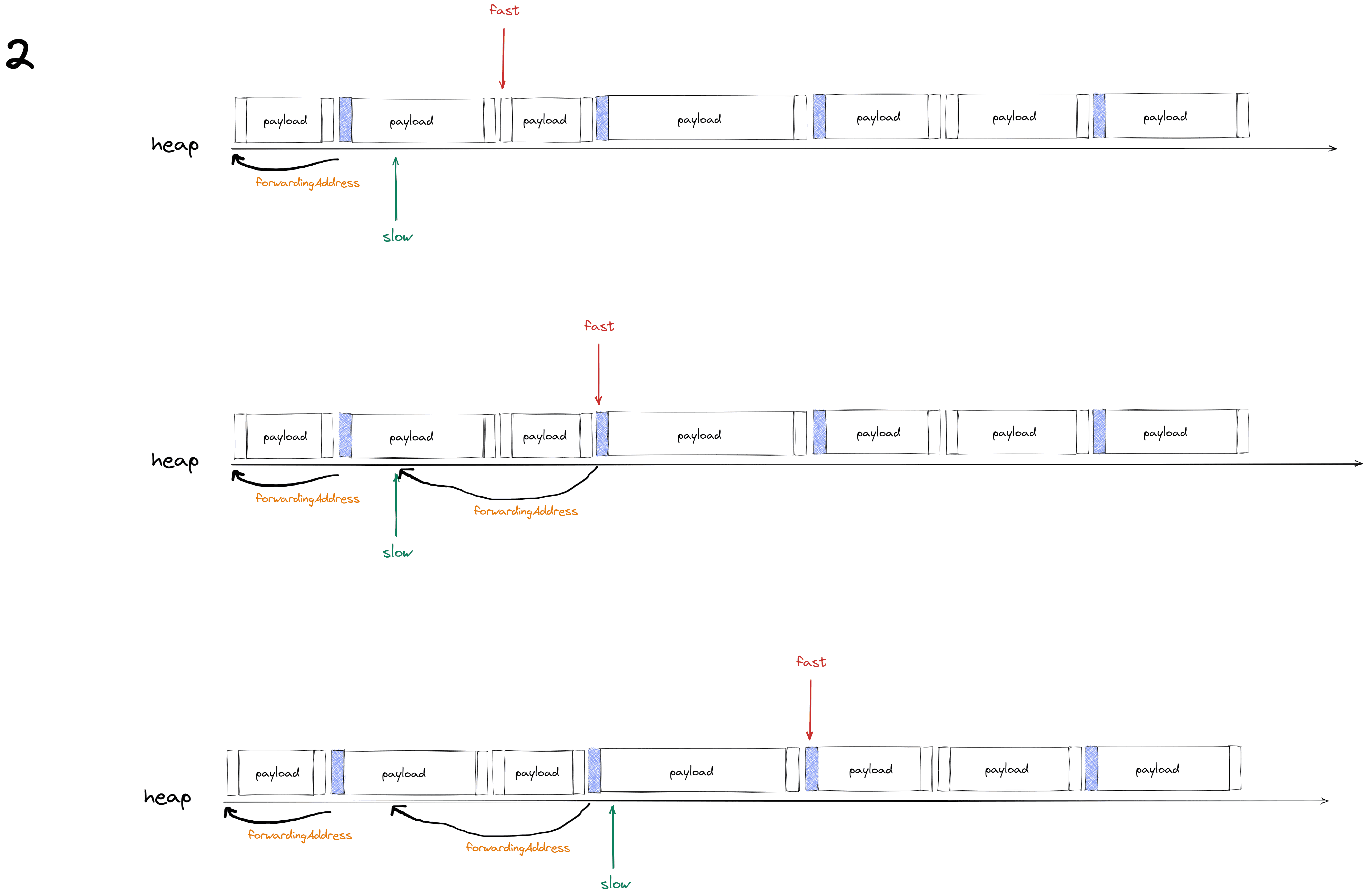
计算所有存活对象的 forwardingAddress转发地址, fast (scan)为快指针,slow(free)为慢指针

 
快指针每次遍历到标记对象时,会给该对象的 header中记录一个 forwardingAddress(上图第11行),值为 慢指针的地址,然后将慢指针向前移动该对象的大小的距离(慢指针每一移动的大小为标记对象的大小,上图第12行),然后快指针继续扫描
第一次堆扫描会先计算出转发地址,步骤如下图所示
updateRefrences
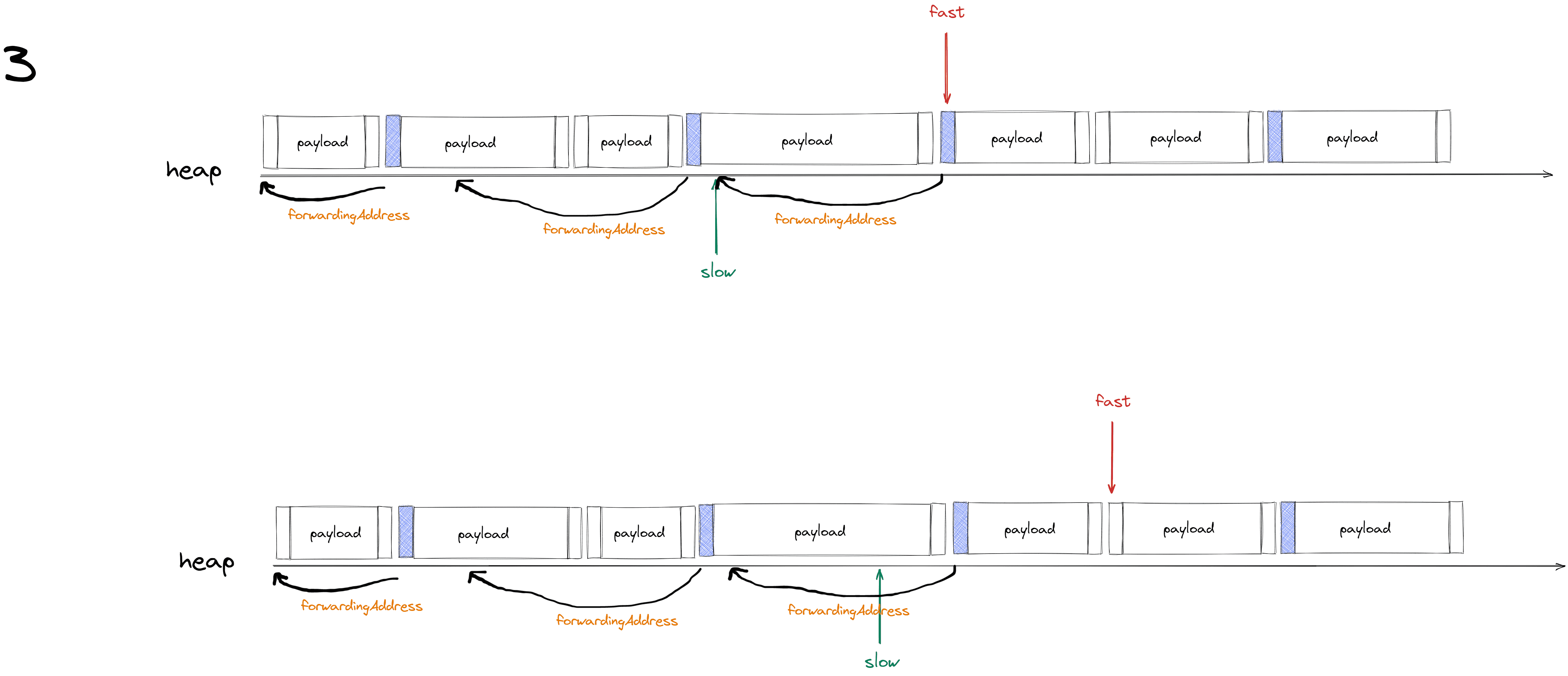
第二次扫描堆会更新 赋值器 中对象的引用地址为 forwardingAddress(转发地址)

 
先将 roots 对象中的引用地址更新为 forwardingAddress(上图第19行)
再将堆中所有存活对象的引用地址更新为 forwardingAddress (上图第26行)
relocate
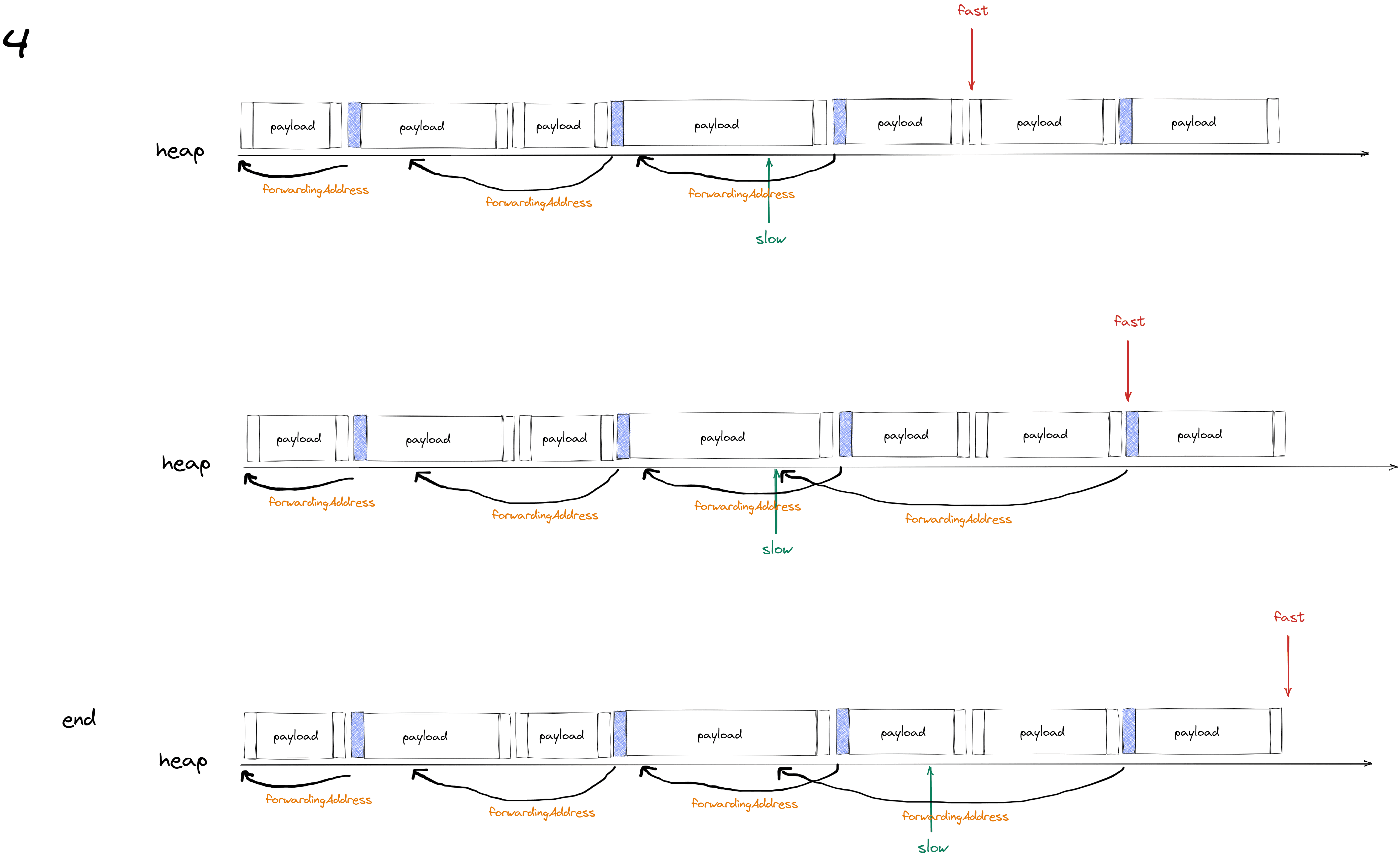
第三次扫描会开始移动对象,继续遍历堆(从低地址往高地址遍历)

 
如果该对象被标记,那么会从该对象的 header中取到 forwardingAddress 将其移动到 forwardingAddress (上图第34行),再将其取消标记。
移动的过程如下图所示
小结
经过三次堆的遍历后,mark-compact就完成了堆中内存的整理,将存活的对象和garbage一分为二。当然该算法还有很多改进的点,回收器可以在 computeLocations的过程中将相邻的garbage进行合并。
单次遍历法
将内存分割成一个个小块,类似于屏幕像素点,然后标记向量和计算偏移量,来达到两次遍历完成对象的移动和指针的更新
问题
对于对象内存较大,且需要长期运行的程序来说,一般都会采用移动式的垃圾回收算法,否则碎片化必然是一个问题,例如java虚拟机都会采用对堆进行整理的移动式回收器
mark-copy (半区域回收)
先将内存划分为两个内存大小相等的空间,分别为 来源空间(from-space) 和 目标空间(to-space)
假定堆是连续的内存空间,然后给对象分配内存的时候会不断的移动 free 指针,当空间不足够的时候,则进行一次 gc
createSemispace():
tospace <- HeapStart
extent <- (HeapEnd - HeapStart) / 2;
max <- fromspace <- HeapStart + extent; // 计算 fromspace 的开始位置
free <- tospace // 将 free 指针标记为 tosapce(目标空间)
// 给对象分配内存地址,同时更新 free 指针
atomic allocate(size):
result <- free
newfree <- result + size; // 更新 free 指针
if(newfree > max) // 内存耗尽,开始 gc
return null
free <- newfree // 更新 free指针
return result // 返回该对象内存地址
gc 流程
以下是核心流程
atomic collect():
flip() // 反转半区
initialise(wroklist) // 将工作列表置空
for each fid in Roots // 遍历roots
process(fid)
// 遍历工作列表
while not isEmpty(wroklist)
ref <- remove(wroklist) // 每次取出一个
scan(ref)
process(fid): // 将对象更新到 to 空间
fromRef <- *fid
if(fromRef != null) // 如果对象没有被处理过,则进行处理
*fid <- forward(fromRef) // 得到新地址
forward(fromRef):
toRef <- forwardingAddress(fromRef) // 获取该对象的新地址
if(toRef == null) // 如果这个对象没有新地址,则将其复制到新地址
toRef <- copy(fromRef) // 得到新地址
return toRef // 将新地址进行返回
copy(fromRef):
toRef = free // 将该对象的地址,设置为最新的 free 地址
free = free + size(fromRef) // 同时更新 free 指针
move(fromRef, toRef) // 将该对象移动到新地址
forwardingAddress(fromRef) <- toRef // 将新地址进行标记,会在原有的内存槽中记录一个转发地址,存的是新地址
add(wroklist, toRef)
return toRef // 将新地址进行返回复制式回收的优势在于,他不需要占用对象头部的额外空间,可以直接将转发地址放在 原来的内存槽中,因为在复制完成后原有的槽不再被使用。 这种方式和双指针算法类似
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处。