Lerna 源码分析之 import-local 下
本文最后更新于:2022年4月22日 上午
import-local 可以让全局和本地安装了同一个模块时,优先使用本地模块
import-local 源码
import-local 主要做了以下几件事
这个模块全局目录,会向上去找最近的
package.json所在的目录拿到这个模块的入口文件 相对于 模块根路径 的相对路径
拿到这个模块在本地的路径(如果本地有安装的情况下)
判断 本地 node_modules 路径 和 全局模块的路径 是否
..开头判断是否加载本地模块
    1. 判断 4 是否为 true
    2. 判断3 是否有值
    3. 判断 3 是否和全局模块入口的地址不相等
以上判断都满足的话,使用本地的模块
require(localFile)不满足的话会
return undefinde,会使用全局的模块
这里我们需要深入看的源码一共有两个
pkgDir.sync(path.dirname(filename)): 向上找到最近的package.json所在的路径resolveCwd.silent(path.join(pkg.name, relativePath)):找这个模块在本地的路径(如果本地有安装)
这一节我们会深入
resolveCwd.silent(path.join(pkg.name, relativePath))
'use strict';
const path = require('path');
const resolveCwd = require('resolve-cwd');
const pkgDir = require('pkg-dir');
module.exports = filename => {
// 拿到这个模块的根路径, 会依次向上查找距离最近的 package.json 目录
const globalDir = pkgDir.sync(path.dirname(filename));
// 得到 模块入口 相对于 模块根路径 的相对路径 (cli.js)
const relativePath = path.relative(globalDir, filename);
// 读取 模块根路径的 package.json
const pkg = require(path.join(globalDir, 'package.json'));
// 取到模块package.json的name,lerna 中 package.json 的 name 属性取到 (lerna)
// 以及 lerna 入口文件相对于 package.json 所在的地址 (cli.js)
// 将 模块根路径 和 模块入口 拼接起来,进行拼接成一个 path (lenam/cli.js)
// 如果本地也有 安装 lerna 会得到本地的 lerna 地址
const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));
// 根据 命令行所在的路径 拼接上 node_modules 生成一个 本地项目node_modules路径
const localNodeModules = path.join(process.cwd(), 'node_modules');
// 判断 本地本地项目node_modules路径 和 这个全局模块所在的目录是否 .. 开头,这个取反,其实没有必要
const filenameInLocalNodeModules = !path.relative(localNodeModules, filename).startsWith('..');
// 如果本地有 lerna 则会加载本地的,否则返回 undefined
return !filenameInLocalNodeModules && localFile && path.relative(localFile, filename) !== '' && require(localFile);
};可以看到 pkgDir.sync(path.dirname(filename)) 主要调用了 pkg-dir 这个库,且将全局的 lerna 入口文件的路径传了进去,例如我这里是('C:\\Users\\37564\\AppData\\Roaming\\npm\\node_modules\\lerna')
resolve-cwd
可以看到 第20 行主要是 使用 resolve-cwd 这个库,而这个库其实也不是主要实现,他主要是调用了 resolve-from 这个库
'use strict';
const resolveFrom = require('resolve-from');
module.exports = moduleId => resolveFrom(process.cwd(), moduleId);
// moduleId: 'lerna\\cli.js'
module.exports.silent = moduleId => resolveFrom.silent(process.cwd(), moduleId);调用的时候,将 **命令行所在的路径 ** 和 Lerna 相对于其 package.json 所在的路径传入进去。我这里的路径是 'E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib' 和 'lerna\\cli.js'
resolve-from
这个库的源码其实也比较简单
接收到传入的 开始查找的路径 和 需要 查找的 模块 (
'lerna\\cli.js')它主要是先通过
Module._nodeModulePaths(fromDirectory)获取这个模块所有可能存在node_modules的paths数组
这里的关键代码是 Module._resolveFilename() 和 Module._nodeModulePaths()
Module._nodeModulePaths()它会根据传入 目录 生成一个所有可能存在node_modules的paths数组Module._resolveFilename()找到一个真实路径,它最主要是根据Module._nodeModulePaths()生成的 paths 数组去查找
Module是node中内置的模块,_resolveFilename其实也是require实现的关键函数,也就是说读完这里面的代码,我们也解开了require的原理。
'use strict';
const path = require('path');
const Module = require('module');
const fs = require('fs');
const resolveFrom = (fromDirectory, moduleId, silent) => {
if (typeof fromDirectory !== 'string') {
throw new TypeError(`Expected \`fromDir\` to be of type \`string\`, got \`${typeof fromDirectory}\``);
}
if (typeof moduleId !== 'string') {
throw new TypeError(`Expected \`moduleId\` to be of type \`string\`, got \`${typeof moduleId}\``);
}
try {
// 找到一个真实路径
fromDirectory = fs.realpathSync(fromDirectory);
} catch (error) {
if (error.code === 'ENOENT') {
fromDirectory = path.resolve(fromDirectory);
} else if (silent) {
return;
} else {
throw error;
}
}
// 这个 noop.js 实际上没有什么作用
const fromFile = path.join(fromDirectory, 'noop.js');
// 开始解析出真实地址
const resolveFileName = () => Module._resolveFilename(moduleId, {
id: fromFile,
filename: fromFile,
// 生成一个所有可能存在的 node_modules 路径数组
paths: Module._nodeModulePaths(fromDirectory)
});
if (silent) {
try {
return resolveFileName();
} catch (error) {
return;
}
}
return resolveFileName();
};
module.exports = (fromDirectory, moduleId) => resolveFrom(fromDirectory, moduleId);
module.exports.silent = (fromDirectory, moduleId) => resolveFrom(fromDirectory, moduleId, true);
生成所有可能存在的路径 Module._nodeModulePaths
在阅读 Module._resolveFilename 之前,我们先查看 Module._nodeModulePaths(),
因为我们刚刚在上面看到了,在查找真实路径之前需要先生成一个 paths 数组(Module._nodeModulePaths(fromDirectory)),而这个数组会根据传入的 路径 生成
例如我们这里传入的是 'E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib',那么就会根据它来生成一个数组,然后将这个数组作为 paths 传给 Module._resolveFilename, 这部分的源码实现包含一部分的算法,值得我们学习
它会主要做以下几件事情
判断路径是否为 根路径,是的话直接返回
[/node_modeles]从后往前 开始遍历这个路径
    1. 每次遍历到下一个 路径分隔符 都会拼接 /node_modules 放到数组
    2. 如果这路径分隔符的目录是 'node_modules' ,则跳过
- 遍历结束后将 根路径(
'/node_modules') 也放到数组中
// node_modules 倒序的 charCode 数组
const nmChars = [ 115, 101, 108, 117, 100, 111, 109, 95, 101, 100, 111, 110 ];
const nmLen = nmChars.length;
Module._nodeModulePaths = function (from) {
// 将模块路径转为绝对路径
from = path.resolve(from);
// 如果路径是 / ,则直接返回 ['/node_modules']
if (from === '/')
return ['/node_modules'];
// 准备一个 paths 数组
// 从后往前开始遍历 路径,每次遍历到路径分隔符时都会在后面拼接上 /node_modules 再push 到 paths
// 每次遍历都会遍历到前一个 路径分隔符
// p 是用来记录 这一小节 遍历的路径中是否包含 node_modules,如果包含,则不 push 到paths 中
// last 可以认为是 这一小节 遍历的 / 的索引位置
const paths = [];
for (let i = from.length - 1, p = 0, last = from.length; i >= 0; --i) {
const code = StringPrototypeCharCodeAt(from, i); // 拿到这次遍历字符串的 charcode
// 如果遍历到路径分割符,且 这一小节 遍历的路径不包含 node_modules, 则 push 到 paths 中
if (code === CHAR_FORWARD_SLASH) {
if (p !== nmLen)
ArrayPrototypePush(
paths,
// 从开头开始截取到这一次 路径分隔符 的位置
StringPrototypeSlice(from, 0, last) + '/node_modules'
);
// 让 last 记录住这一次 路径分隔符的 位置,下一次截取的时候就截取到这个位置
last = i;
// 将 p 初始化
p = 0;
} else if (p !== -1) {
// 只有第一次遍历时和每次 push 完和初始化 p 后都将进入这个分支
// 会判断这一次遍历的字符串是否和 倒序的 node_modules charcode 数组相等
// 例如:第一次我们这里是 b,b 的 charcode 和 s 的 charcode 不相等,
// 那么直到遍历到下一个路径分隔符之前,都没有必要在去判断后续的字符串是否和 node_modules 相等了
// 如果 这个字符串一直到遍历到下一个路径分隔符之前,都完美命中了 node_modules 字符串,则push到 paths 时会跳过这个路径
// 所以这个判断条件最主要是判断路径中是否包含 node_modules
if (nmChars[p] === code) {
++p;
} else {
// 只要这个字符串和 node_modules 中对应的不一致,让 p = -1,直到遍历到下一个 路径分隔符
p = -1;
}
}
}
// 最后将根路径的 node_modules push 到 paths 中
ArrayPrototypePush(paths, '/node_modules');
return paths;
};Module._nodeModulePaths() 主要是帮我们生成所有可能存在的路径数组,列如我们在项目中引入了 koa,那它会生成一个逐级向上的一个目录,且每个目录后会带上 node_modules,
这里需要注意的是,如果路径中已经存在 node_modules,则不会将这一级目录push 到 paths 中。
如何校验这个路径包含 node_modules
准备知识
nmChars: 是一个
'node_modules'倒序 ('seludom_edon') 的一个charcode数组([ 115, 101, 108, 117, 100, 111, 109, 95, 101, 100, 111, 110 ])nmLen: 是这个数组的长度 (12)
以下我会把 一个路径分割符 到 下一个路径分隔符 之间的遍历 称之为 一小节的遍历,如 \\lib 是一小节,\\core 是一小节遍历
例如,我的路径为 'E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib',
便利时 会从后往前遍历 ,所以第一次会拿到 字符串b 的charcode ,那么就会拿着 字符串b 的charcode 和 字符串 s 的charcode 做比较,
如果不相等,那么直到下一个路径分隔符之前的遍历( 字符串 i, b的charcode ) 都不需要做比较了,这个优化的关键就是 变量p 。
如果相等,那么 p会 +1 ,表示这一次命中了,下一轮遍历的时候,就会和 字符串 e 的charcode (node_modules 字符串charcode的倒序数组) 比较,如果依旧相等,则会依次比较下一位字符串。
当遍历到 路径分隔符 \\ 时,会判断从上个 路径分隔符 到这一个 路径分隔符 之间的 路径字符串 是否为 node_modules (很明显,这里我们不是,我们第一小节的遍历是 \\lib),
- 如果不是,就会将刚刚遍历的路径拼接上
/node_modules后放到paths数组中,且将 p初始化,这样下一小节遍历的时候又会去拿着这一小节的第一个字符串 (e)和 node_modules 字符串charcode的倒序数组 (s) 的 charcode做比较
这里源码中其实会区分
win和unix环境做不同的判断,因为不同环境的路径分隔符不一样,但是主要逻辑基本是一致的,上述贴的源码是unix中的
最后paths 会得到类似于这样的一个数组
[
"E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib\\node_modules",
"E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\node_modules",
"E:\\learn\\learn-cli\\sunshine-cli\\packages\\node_modules",
"E:\\learn\\learn-cli\\sunshine-cli\\node_modules",
"E:\\learn\\learn-cli\\node_modules",
"E:\\learn\\node_modules",
"E:\\node_modules",
]准备查找Modeule._resolveFilaname
当我们通过 Module._nodeModulePaths 拿到一个 paths 数组后,就可以开始执行 Module._resolveFilename 的逻辑了
const resolveFileName = () => Module._resolveFilename(moduleId, {
id: fromFile,
filename: fromFile,
// 生成一个所有可能存在的 node_modules 路径数组
paths: Module._nodeModulePaths(fromDirectory)
});Module._resolveFilename 主要会做以下三件事
判断是否为内置模块
调用
Module._resolveLoopUpPaths()将环境变量中的paths和Module._nodeModulePaths生成的paths进行合并 ,得到一个更全的paths数组调用
Module._findPath()开始查找模块的真实路径
Module._resolveFilename = function(request, parent, isMain, options) {
// 1. 判断是否内置模块
if (NativeModule.canBeRequiredByUsers(request)) {
return request;
}
let paths;
if (typeof options === 'object' && options !== null) {
...
} else {
// 2. 与环境变量中的 paths 进行合并
paths = Module._resolveLookupPaths(request, parent);
}
if (parent && parent.filename) { ... }
// 尝试自解析
const parentPath = trySelfParentPath(parent);
const selfResolved = trySelf(parentPath, request);
if (selfResolved) {
// 做缓存
const cacheKey = request + '\x00' +
(paths.length === 1 ? paths[0] : ArrayPrototypeJoin(paths, '\x00'));
Module._pathCache[cacheKey] = selfResolved;
return selfResolved;
}
// 3. 开始调用 Module._findPath() 查找模块真实路径
const filename = Module._findPath(request, paths, isMain, false);
if (filename) return filename;
...
};开始查找Module._findPath
Module._findPath() 主要做以下几件事
将
模块名和paths通过\x00(十六进制的 ‘’ )来生成一个chacheKey先从缓存中尝试获取
开始遍历
paths逐级向上查找(paths 已经是从下往上排好的顺序)
    1. 判断是否为一个目录,不是目录则跳过跳过,进入下一轮遍历
    2. 拼接 path 和 模块名,生成 basePash
    3. 如果这个basePash 是一个文件路径, 调用 toRealPath(basePath) 查找真实路径
    4. 如果没有找到会尝试用 basePash 再拼接上 扩展名 ([ '.js', '.json', '.node' ]) 去找
    5. 如果这个basePash 是一个目录,调用 tryPackage() 去查找
Module._findPath = function (request, paths, isMain) {
// 是否路径转换
const absoluteRequest = path.isAbsolute(request);
if (absoluteRequest) {
paths = [''];
} else if (!paths || paths.length === 0) {
return false;
}
// 1. 生成 cacheKey
// 会将 url 和 所有的 paths 通过 '' 来生成一个 cacheKey
// 为什么要通过 \x00 因为,后面可以通过 \x00 来分割
const cacheKey = request + '\x00' + ArrayPrototypeJoin(paths, '\x00');
// 2. 尝试从缓存中取
const entry = Module._pathCache[cacheKey];
if (entry)
return entry;
let exts;
let trailingSlash = request.length > 0 &&
StringPrototypeCharCodeAt(request, request.length - 1) ===
CHAR_FORWARD_SLASH;
// 判断尾部是否为 / 结尾
if (!trailingSlash) {
// 正则 /(?:^|\\/)\\.?\\.$/ 判断尾部 是否 /.. /. .. . 结尾
trailingSlash = RegExpPrototypeTest(trailingSlashRegex, request);
}
// 1. 开始遍历paths
// For each path
for (let i = 0; i < paths.length; i++) {
// Don't search further if path doesn't exist
const curPath = paths[i];
// 0是文件 1是目录, 负数表示没有这个模块,如果没有这个模块,则直接跳过以下逻辑
if (curPath && stat(curPath) < 1) continue;
if (!absoluteRequest) { ... }
// 2. 将两个路径进行拼接
const basePath = path.resolve(curPath, request);
let filename;
const rc = stat(basePath);
if (!trailingSlash) { // 不是 //. 等方式结尾
if (rc === 0) { // File. 如果找到了这个文件
if (!isMain) { // 传入的是 false
if (preserveSymlinks) { // 是否保留软链接
filename = path.resolve(basePath);
} else {
// 开始解析路径
// 'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\lerna\\cli.js'
filename = toRealPath(basePath);
}
} else if (preserveSymlinksMain) {
...
} else {
...
}
}
if (!filename) {
// 如果上述没有找到尝试通过扩展名去解析,
// 会依次尝试 [ ".js", ".json", ".node", ] 去解析
if (exts === undefined)
exts = ObjectKeys(Module._extensions);
filename = tryExtensions(basePath, exts, isMain);
}
}
if (!filename && rc === 1) { // Directory. // 表示这是一个目录
// 尝试加载目录下 index .js .node .node 解析
if (exts === undefined)
exts = ObjectKeys(Module._extensions);
filename = tryPackage(basePath, exts, isMain, request);
}
// 如果找到了真实地址,则将其缓存
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
return false;
};这一步生成 真实路径最主要的是 toRealPath(basePath) 来生成的。
toRealPath()
toRealPath() 的源码很简单,但其最主要的逻辑其实是在 fs.realpathSync() 中,
这里将上一步生成的 basePash 和当前已经加载过得所有缓存作为对象的属性传入进去
这个属性的 key名 是一个 Symbol,key值 是一个 Map对象,所以我们需要深入的看 fs.realpathSync() 的源码实现
function toRealPath(requestPath) {
return fs.realpathSync(requestPath, {
[internalFS.realpathCacheKey]: realpathCache
});
}软链接转真实地址fs.realpathSync
fs.realpathSync() 主要做以下几件事
先从全局缓存 (
cache) 中尝试获取从左往右遍历这个路径字符串,依次将每个路径转换为真实路径
    1. 尝试从缓存中尝试获取,如果是取到的是一个真实地址则 continue,否则 中断
    2. 取到这个路径或文件的 lstat,判断是否为软连接,如果不是则将其缓存,并且 重新执行第 2 步
    3. 如果是一个软链接,则会通过 binding.readlink() 解析出真实地址
    4. 并将软链接的真实地址缓存到 cache,在 unix 系统 中还会缓存在 seenLinks
    5. 将真实地址和 文件后缀 进行拼接,然后 重新执行第2 步 ,因为拼接后的路径依旧有可能有软链接(使用 pnpm 的话就会有很多软链接),所以需要再次循环,转换为真实地址,但是后续会更快,因为之前做过缓存
遍历结束后,将其 原始地址 作为
key,真实地址作为value缓存,返回真实路径
function realpathSync(p, options) {
// 'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\lerna\\cli.js'
// Symbol(realpathCacheKey): Map(84)
options = getOptions(options, emptyObj);
p = toPathIfFileURL(p); // 判断是否为网络地址
if (typeof p !== 'string') {
p += '';
}
validatePath(p);
p = pathModule.resolve(p); // 将其转换为一个绝对路径
// 取到传入的所有缓存
const cache = options[realpathCacheKey];
const maybeCachedResult = cache && cache.get(p); // 尝试从缓存中取
if (maybeCachedResult) {
return maybeCachedResult;
}
// 创建两个没有原型链的 对象
const seenLinks = ObjectCreate(null);
const knownHard = ObjectCreate(null);
const original = p; // 将原始地址记下来
// 当前字符在 p 中的位置
let pos;
// 到目前为止的部分路径,包括尾部斜杠(如果有)
let current;
// 不带斜杠的部分路径(指向根时除外)
let base;
// 上一轮扫描的部分路径,带斜线
let previous;
/*
跳过根
这个根在 win 和 unix 中不太一致
win 是 'C:\\' 或者 'D:\\' 的这种路径
unix 是 '/'
*/
current = base = splitRoot(p);
pos = current.length;
// 在 Windows 上,检查根是否存在。在 unix 上没有必要。
if (isWindows) {
const ctx = { path: base };
binding.lstat(pathModule.toNamespacedPath(base), false, undefined, ctx);
handleErrorFromBinding(ctx);
knownHard[base] = true; // 将真实路径放到缓存中
}
// 从左往右依次校验这个路径,将路径转换成真实地址(如果是软连接的话)
//注意:p.length 变化。
// 第二次进来,会带上一个真实地址,但是还需要遍历一遍,因为它依旧有可能是一个软链接,
// 比如这次的地址后面有 .pnpm 这部分的路径在上一次是没有便利到的
// 但是这次遍历会很快,应该有缓存
// 'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\.pnpm
// \\registry.nlark.com+lerna@4.0.0\\node_modules\\lerna\\cli.js'
while (pos < p.length) {
// 取到下一次的 / 的位置
const result = nextPart(p, pos);
previous = current; // 记录上一次的路径 'E:\\learn\\'
if (result === -1) {
const last = p.slice(pos);
current += last;
base = previous + last;
pos = p.length;
} else { // 取到了下一个路径分隔符 /
// 'E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib'
// 用根路径将其拼接 'E:\\learn\\' (3, 8)
current += p.slice(pos, result + 1); // 'E:\\learn\\'
base = previous + p.slice(pos, result); // 'E:\\learn'
// 将下一个路径分隔符 / 的索引 赋值给 pos,下一次遍历的时候就会从 这个 索引 开始,
// 可以理解为 learn-cli 的位置
pos = result + 1;
}
// 从缓存中取,如果不是软链接则继续,否则 中断
if (knownHard[base] || (cache && cache.get(base) === base)) {
if (isFileType(statValues, S_IFIFO) ||
isFileType(statValues, S_IFSOCK)) {
break;
}
continue;
}
let resolvedLink;
const maybeCachedResolved = cache && cache.get(base);
if (maybeCachedResolved) { //如果缓存中有则直接使用缓存中
resolvedLink = maybeCachedResolved;
} else {
// 直接使用 stats 数组,避免只创建 fs.Stats 实例
// 供我们内部使用。
// 匹配的设备根路径,将路径转换为长UNC路径
const baseLong = pathModule.toNamespacedPath(base);
const ctx = { path: base };
const stats = binding.lstat(baseLong, true, undefined, ctx); // 路径的或文件的 lstat
handleErrorFromBinding(ctx);
// 判断这个路径是否为软链接 40960,如果不是则将其缓存并且直接跳到下一轮循环
if (!isFileType(stats, S_IFLNK)) {
// 将所有查找过地址都缓存在 knownHard 中,第二次找的时候就会很快
knownHard[base] = true;
if (cache) cache.set(base, base);
continue;
}
// 进入到这里表示这个路径是一个软链接
let linkTarget = null; // 用来保存软链接的真实路径
let id;
// dev/ino 在 Windows 上总是返回 0,所以跳过检查。
if (!isWindows) {
const dev = stats[0].toString(32); // 文件在这台设备上的id
const ino = stats[7].toString(32); // 这个文件在文件管理器上的 id
id = `${dev}:${ino}`; // 这个组合的 id 是唯一的
if (seenLinks[id]) { // 如果缓存中有则从缓存中取
linkTarget = seenLinks[id];
}
}
// 如果是 windows 或者缓存中没有取到就会是 null
// 这里开始通过软链接来解析出真实路径
if (linkTarget === null) {
const ctx = { path: base };
binding.stat(baseLong, false, undefined, ctx);
handleErrorFromBinding(ctx);
// 通过软链接,解析出一个真实路径
linkTarget = binding.readlink(baseLong, undefined, undefined, ctx);
handleErrorFromBinding(ctx);
}
// 将软链接和真实地址进行拼接,会得到一个真实地址
resolvedLink = pathModule.resolve(previous, linkTarget);
// 将其缓存
if (cache) cache.set(base, resolvedLink);
if (!isWindows) seenLinks[id] = linkTarget;
}
// 拿到 真实路径 后和 需要加载的文件名称拼接起来,然后重新循环,因为拼接后的地址也可能是一个软链接
p = pathModule.resolve(resolvedLink, p.slice(pos));
// 跳过根
current = base = splitRoot(p);
pos = current.length;
// 在 Windows 上,检查根是否存在。在 unix 上没有必要。
if (isWindows && !knownHard[base]) {
const ctx = { path: base };
binding.lstat(pathModule.toNamespacedPath(base), false, undefined, ctx);
handleErrorFromBinding(ctx);
knownHard[base] = true;
}
}
// 当遍历结束后 会将 original源地址 和 真实地址 存起来,后续遍历的时候会更快
/*
'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\lerna\\cli.js'
'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\.pnpm
\\registry.nlark.com+lerna@4.0.0\\node_modules\\lerna\\cli.js'
*/
if (cache) cache.set(original, p);
return encodeRealpathResult(p, options);
}当把路径依次从左往右遍历结束后,会得到这种路径的真实路径,因为原始路径有可能会存在 软链接,这个时候就会开始跳出循环,将真实地址一级一级 ruturn出去
什么是软链接?
软链接,表示这个路径不是一个真实存在路径,在windows 可以理解为快捷方式,
例如我这里是一个软链接 'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\lerna'
软链接如何转换为真实地址?
软链接 和 真实地址 的转换是通过 linkTarget = binding.readlink(baseLong, undefined, undefined, ctx);来实现的,如果要看这里具体是怎么实现的,就需要查看 v8 的源码了
为什么转换为真实地址后还需要再次遍历?
因为这个真实地址中可能依旧存在软链接,所以需要再次遍历,但是这次的遍历会更快,因为之前已经做过缓存,
例如如下两个链接
{
previous: "E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\",
linkTarget: "E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\.pnpm\\registry.nlark.com+lerna@4.0.0\\node_modules\\lerna\\",
}
通过 p = pathModule.resolve(resolvedLink, p.slice(pos)); 得到的结果如下,这个结果与文件后缀进行拼接后依旧有可能是软链接
'E:\\learn\\learn-cli\\sunshine-cli\\node_modules\\.pnpm\\registry.nlark.com+lerna@4.0.0\\node_modules\\lerna'什么是 lstat ?
文件的描述信息,具体的可以在 这里查看,这里只用到了两个属性 dev 和 ino
dev 文件在这台设备上的id
ino 这个文件在文件管理器上的 id
当遍历结束跳出循环后将 original 作为key,将 真实地址 作为 value 缓存,然后将 真实地址 return,到这里节结束了,会一路return 到 resolveCwd.silent 的位置
'use strict';
const resolveFrom = require('resolve-from');
module.exports = moduleId => resolveFrom(process.cwd(), moduleId);
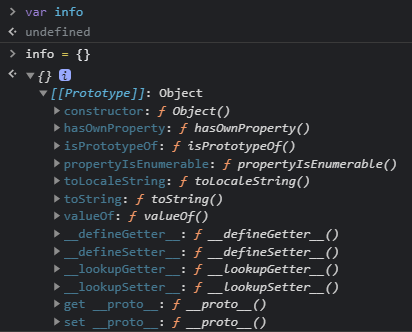
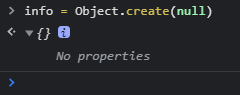
module.exports.silent = moduleId => resolveFrom.silent(process.cwd(), moduleId);为什么通过ObjectCreate(null) 创建对象
这个 ObjectCreate(null) 其实就是 Object.create(null) ,通过它创建的对象是一个纯粹的对象,没有原型链
对线字面量的方式创建的对象
Object.create(null) 的方式创建的对象
加载本地 Leran
通过以上一系列的过程,这里终于把 resolveCwd.silent 的逻辑执行结束了,拿到了一个本地的真实路径
'use strict';
const path = require('path');
const resolveCwd = require('resolve-cwd');
const pkgDir = require('pkg-dir');
module.exports = filename => {
const globalDir = pkgDir.sync(path.dirname(filename));
const relativePath = path.relative(globalDir, filename);
const pkg = require(path.join(globalDir, 'package.json'));
const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));
const localNodeModules = path.join(process.cwd(), 'node_modules');
const filenameInLocalNodeModules = !path.relative(localNodeModules, filename).startsWith('..');
return !filenameInLocalNodeModules && localFile && path.relative(localFile, filename) !== '' && require(localFile);
};紧接着,会在 当前命令行的路径 拼接上 node_modules (第10行)得到一个路径,
然后调用 path.relative(localNodeModules, filename) 来根据获取当前目录返回从这个 路径 到 模块的真实路径 的相对路径
例如:
path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb');
// 返回: '../../impl/bbb'获取到这个相对路径后通过 starWith('..') 判断这个路径是否为 .. 开头
最后这一行的判断是
先判断是否为这个相对路劲是否
..开头本地是否包含这个模块
本地模块的路径和全局模块的路径不是同一个
require(localFile)开始加载本地 Leran
return !filenameInLocalNodeModules && localFile && path.relative(localFile, filename) !== '' && require(localFile);可以看到上方输出了info cli using local version of lerna,表示我们这里加载的是本地的 leran

import-local 的bug
这里一开始在调试的时候发现 lerna 始终加载不了,后面发现是下面这一行代码的问题,且这个问题只会出现在 windows 上
先来看一下这段代码
'use strict';
const path = require('path');
const resolveCwd = require('resolve-cwd');
const pkgDir = require('pkg-dir');
module.exports = filename => {
const globalDir = pkgDir.sync(path.dirname(filename));
const relativePath = path.relative(globalDir, filename);
const pkg = require(path.join(globalDir, 'package.json'));
const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));
const localNodeModules = path.join(process.cwd(), 'node_modules');
const filenameInLocalNodeModules = !path.relative(localNodeModules, filename).startsWith('..');
return !filenameInLocalNodeModules && localFile && path.relative(localFile, filename) !== '' && require(localFile);
};主要的问题在这行!path.relative(localNodeModules, filename).startsWith('..')
这行代码乍一看没啥问题,他调用了 path.relative 来得到一个相对路径,然后来判断是否为 .. 开头
path.relative() 方法根据当前工作目录返回从 from 到 to 的相对路径。 如果 from 和 to 都解析为相同的路径(在分别调用 path.resolve() 之后),则返回零长度字符串。
path.relative('/data/orandea/test/aaa', '/data/orandea/impl/bbb');
// 返回: '../../impl/bbb'为什么说在windows 上会出现问题呢,这是因为在 windows 上一般我们都会给一块硬盘分不同的区,例如 C、D、E盘,不同的盘存放不同的文件,设想这样一种场景,我们通过 npm 全局安装的模块默认一般在C盘,如果我们的工作目录在其它盘,如E盘,这个时候就会出现问题了,如下所示,
path.relative(
'E:\\learn\\learn-cli\\sunshine-cli\\packages\\core\\lib\\node_modules',
'C:\\Users\\37564\\AppData\\Roaming\\npm\\node_modules\\lerna\\cli.js'
)
// C:\Users\37564\AppData\Roaming\npm\node_modules\lerna\cli.js这里就会直接返回一个绝对路径了,不存在 .. 开头,一般在 unix 系统上是有一个根目录 / 的,所以路径不会有问题 ,如果解决该问题呢,将代码改成以下
fileInLocalPath.startsWith('..') || (os.type() === 'Windows_NT' && path.isAbsolute(fileInLocalPath));
这行代码意思是,如果路径不是以 .. 开头,则会判断windows 系统,并且这个路径是一个绝对路径,这个库最近一个版本已经发布两年了,很好奇其他人是否又遇到这个bug,改完后给这个库提了一个 pr,希望其它使用者不会出现这个问题
'use strict';
const path = require('path');
const resolveCwd = require('resolve-cwd');
const pkgDir = require('pkg-dir');
const os = require('os');
module.exports = filename => {
const globalDir = pkgDir.sync(path.dirname(filename));
const relativePath = path.relative(globalDir, filename);
const pkg = require(path.join(globalDir, 'package.json'));
const localFile = resolveCwd.silent(path.join(pkg.name, relativePath));
const localNodeModules = path.join(process.cwd(), 'node_modules');
const fileInLocalPath = path.relative(localNodeModules, filename);
const filenameInLocalNodeModules = fileInLocalPath.startsWith('..') || (os.type() === 'Windows_NT' && path.isAbsolute(fileInLocalPath));
return filenameInLocalNodeModules && localFile && path.relative(localFile, filename) !== '' && require(localFile);
};流程图
最后附上一张 完整的流程图
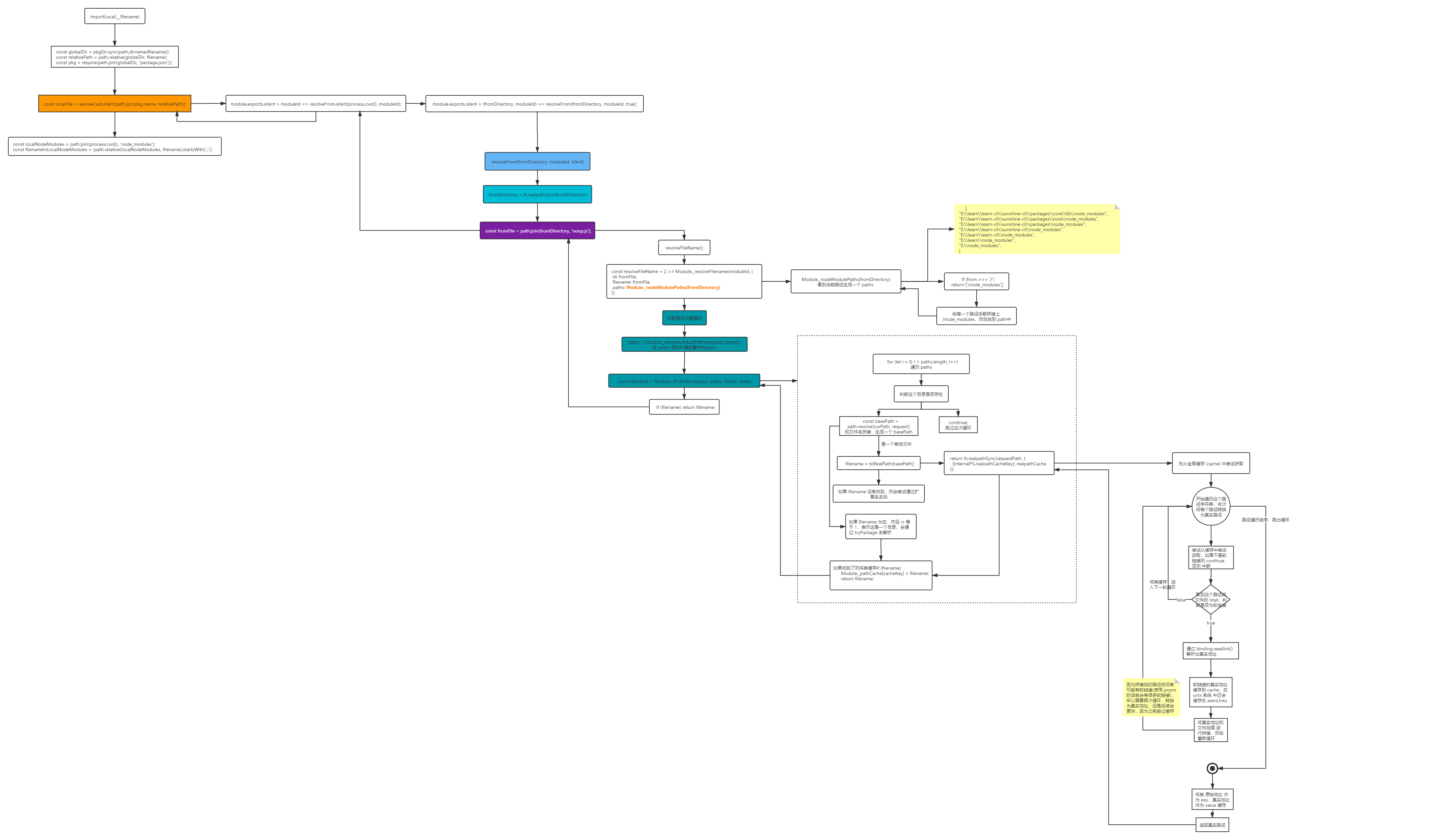
    
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处。