前端模块化规范
本文最后更新于:2022年4月22日 上午
CommonJS、AMD、CMD、ES6 模块化规范,及深入了解 CommonJS 模块化规范
随着js 的发展,早期js没有模块化规范,
node加载文件的顺序其实像一个图结构,按照深度优先的算法来加载
AMD 规范
amd规范主要通过 request.js 库来实现,基本用法如下,
通过npm安装的jquery源码中也是使用的 AMD 规范的
index.html<script src="./lib/require.js" data-main="./index.js" ></script>此处的模块路径会自动加上 .js 后缀,不用手动加,手动加了会报错
index.js(function () {
require.config({
baseUrl: '',
paths: {
foo: './modules/foo',
bar: './modules/bar',
}
})
require(['foo', 'bar'], function (foo,bar) {
console.log(foo,bar); // {age: 18} {name: "abc"}
})
})()通过 define 方法导出变量
modules/bar.jsdefine(
(function () {
let name = 'abc'
return { name }
})()
)通过 define 方法导出变量
modules/foo.jsdefine(
(function () {
let age = 18;
return { age }
})()
)CMD 规范
CMD 规范主要通过sea.js来实现的
index.html<script src="./lib/sea.js"></script>
<script>
seajs.use('./index.js')
</script>index.jsdefine(function (require, exports, module) {
let foo = require('./foo')
console.log(foo);
})foo.jsdefine(function (require, exports, module) {
module.exports = {
name: 'abc',
age: 18
}
})CommonJS
导出:module.exports exports
在node中我们导出一些数据的时候既可以使用 module.exports,又可以使用 exports 来导出,那 node 内部到底是做了什么操作
找到对应的源码,可以看到下面这行代码,
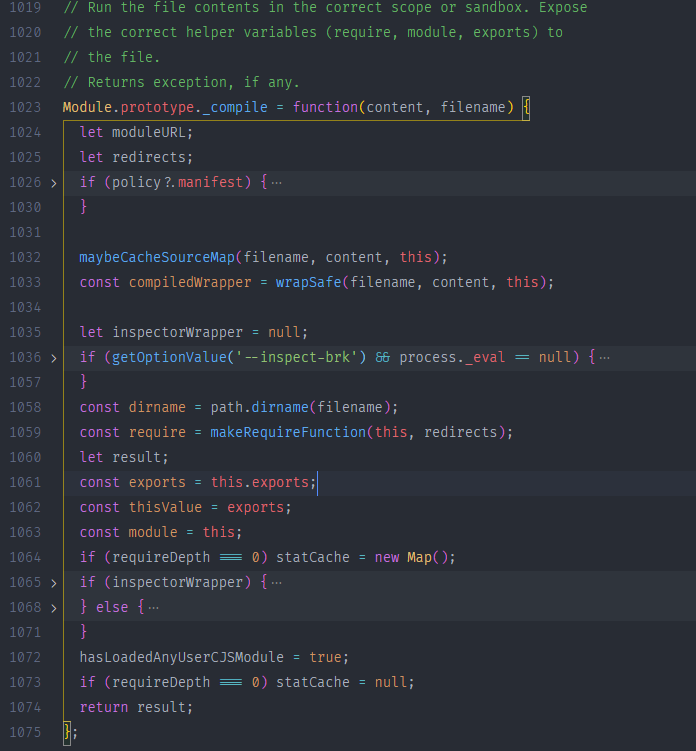
在 1061行可以看到,node帮我们做了一个const exports = this.exports,这个this就是当前模块的实例,在node中,每个文件都是一个Module的实例,所以我们在导出的时候才可以使用以下两种方式,因为他们指向的是同一个堆内存地址
源码 lib\internal\modules\cjs\loader.js
exports.name = 'node';
exports.age = 18;
module.exports = {
name: 'node',
age: 18
}导入: require
在CommonJs中我们使用的是 require() 导出,它实际上是module原型上的一个方法,在node中,每个文件都是一个Module的实例,这个实例中包含很多的属性及方法,其中 require() 就是其中负责导入的方法
为了进一步验证,我在源码中找到了这个位置,从源码中可以看到 require() 方法是添加在 module 原型上的
1. 调用 Module.prototype.require() 方法
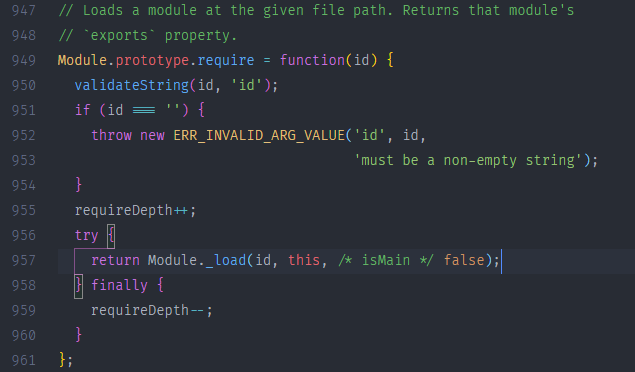
在上图中可以看到 require() 其主要的实现是调了 Module._load() 方法,我们来简单看一下 Module._load()
2. 调用 Module._load() 方法
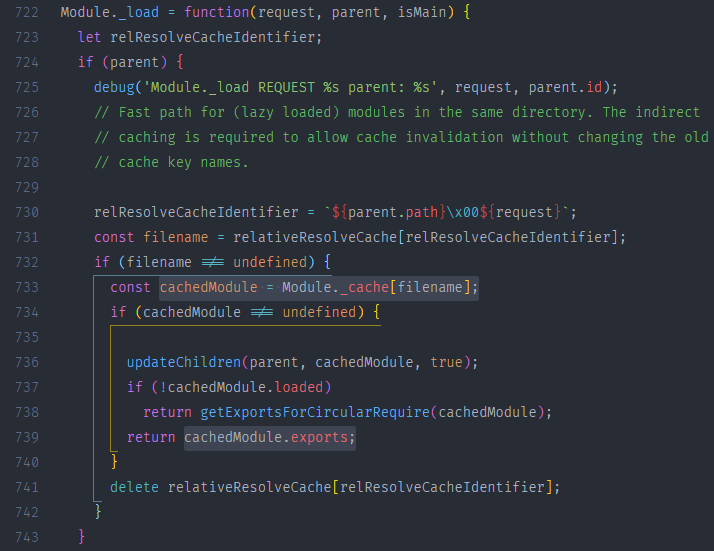
Module._load()方法会做这几件事- 首先在缓存中查找该模块,如果该模块已经被缓存,则会直接返回该模块的 exports
- 如果该模块是一个本地模块,则会调用
NativeModule.prototype.compileForPublicLoader()并返回其 exports - 如果上述都没定位到文件,则会为该文件新建一个模块保存到缓存中,然后读取其中内容并将其返回其 exports
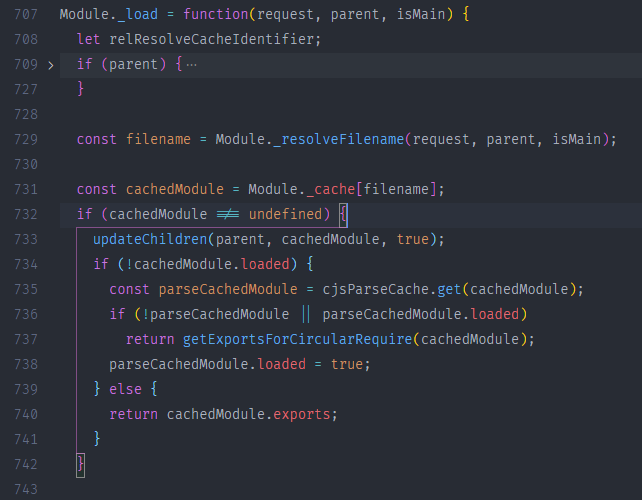
若该文件初次引入,还未添加到缓存,在上图中 729 行 node 会调用 Module._resolveFilename() 方法来找到文件的绝对路径
2.1文件未被缓存
文件未被缓存则会 调用 Module._resolveFilename() 方法来获取文件文件的绝对路径
该方法中 主要通过 Module._resolveLookupPaths 和 Module._findPath()两个方法来找到文件路径,前者会返回一个paths 数组,后者会返回一个确切的文件绝对路径
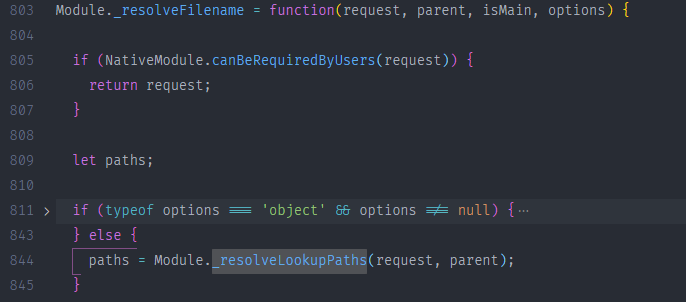
2.1.1查找文件
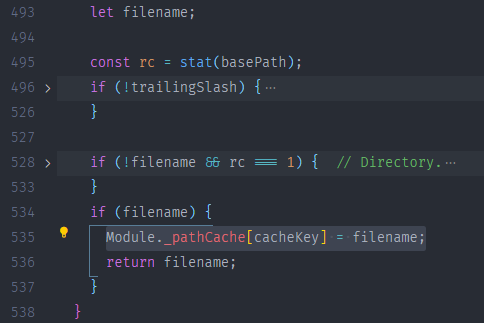
上面代码会返回一个文件可能会出现的 paths 数组,把这个 paths 数组传入Module._findPath() 方法来返回一个确切的绝对路径,如果找到则直接返回文件路径,找不到则报错
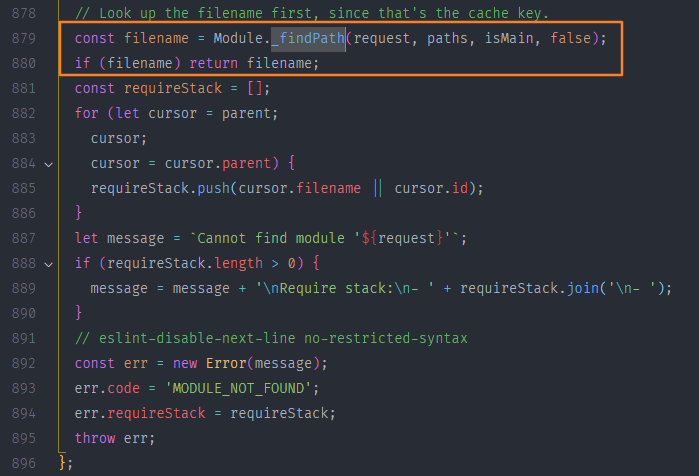
2.1.2查找目录
在 Module._findPath() 查找的过程中 node会先分析文件的扩展名,如果分析完文件扩展名后依旧没有定位到文件,但是找到了一个目录,那么 node 会把这个目录当成一个包package 来处理,当node 把这个目录当成包来处理的时候
node 会先在该目录先查找名为
package.json文件,该行为是node对CommonJS包规范支持的行为并从中找到 main 属性,以该值的文件名为入口,如果没有找到 main 或者该值是错误的,则会依次按照index.jsindex.jsonindex.node的顺序来查找完全符合CommonJS规范的包目录应该包含如下这些文件。
- package.json:包描述文件。
- bin:用于存放可执行二进制文件的目录。
- lib:用于存放JavaScript代码的目录。
- doc:用于存放文档的目录。
- test:用于存放单元测试用例的代码。
如果该过程中没有找到文件,则会进入到下一个模块路径
该路径是一个数组,该数组是node在定位文件位置时 调用的 Module._resolveLookupPaths() 生成的文件可能存在的路径数组,如果该数组遍历结束依旧没有找到,node 则会将其抛出一个错误
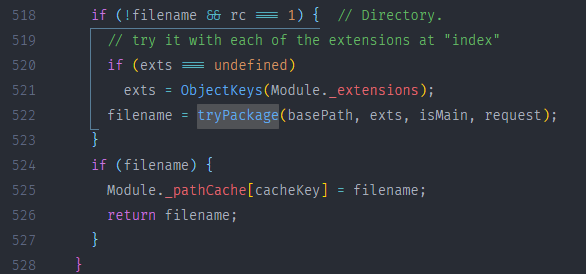
上面代码为 Module._findPath() 查找时没有定位到文件后,找到了一个目录,那么它会调用 tryPackage() 方法来查找目录,
tryPackage() 内部首先调用 readPackage() 来将该目录当成一个包来处理,并先尝试读取该目录下的 package.json 中的 main 属性
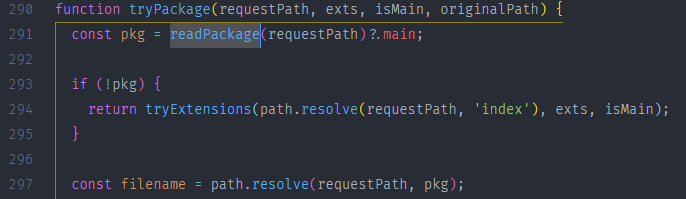
readPackage() 内部做的操作就是帮我们读取 package.json 并将其内容 JSONParse()转为对象后将其结果返回
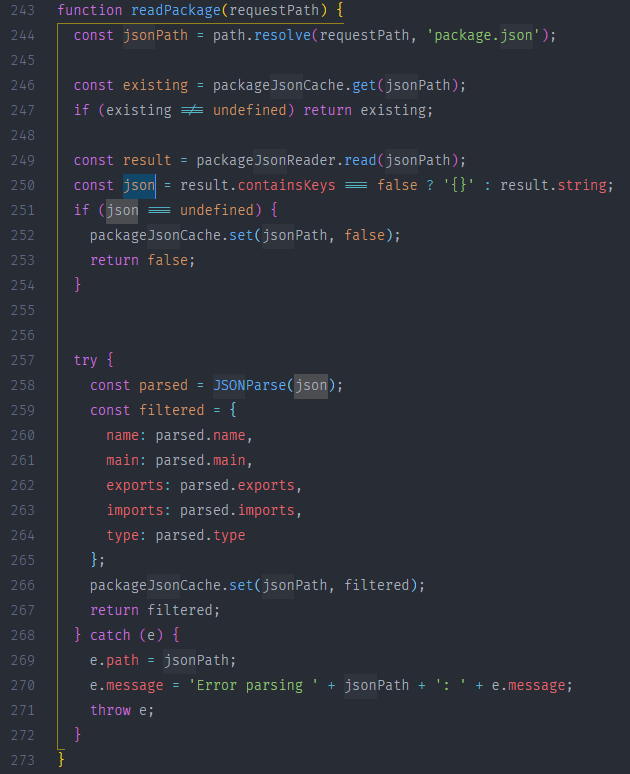
若在 readPackage() 后没有找到 package.json 或者 main 属性有误, 则会依次按照 index.js index.json index.node 的顺序来查找,并将结果返回

2.1.3 查找成功,设置缓存
在整个查找过程结束后,如果找到了,则会将其缓存,再把结果返回
2.1.2查找文件失败
若 Module._findPath() 结束后没有没有定位到文件
在 Module._resolveFilename() 则抛出一个错误,这个错误也是我们在控制台中最常见的
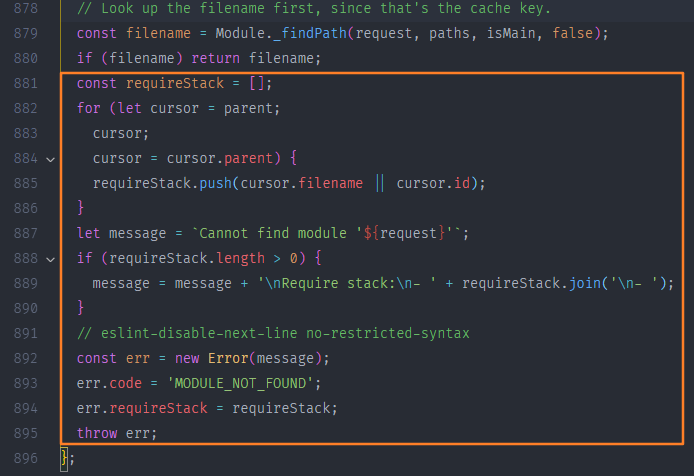
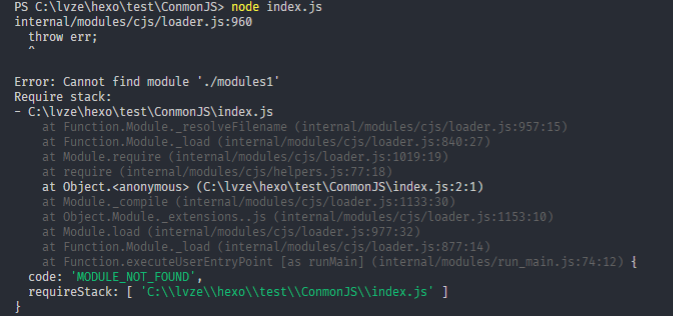
一起来看一下这个错误
2.2文件已被缓存
直接取出缓存返回
完整流程图
如不清晰可点击图片下载后放大查看

require查找简单示例图
目录结构如下
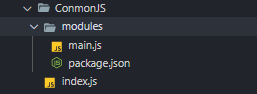
在 index.js 中导入了 ./modules
index.jsrequire('./modules')modules/package.json{
"main":"./main.js"
}modules/main.jsconsole.log('我是main.js中的输出');接下来在 终端中运行我们的index.js
bashPS C:\CommonJS> node index.js
会得到以下的输出node
bashPS C:\CommonJS> node index.js 我是main.js中的输出
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议,转载请注明出处。